如何用 n8n 和 LLM 自动分类邮件
我已经厌倦了继续等 Gmail 自己搞明白哪些邮件对我真的重要。让 AI 接管我的个人邮件分类三个月之后,我已经无法想象再回到手动整理的状态。
我的系统简单得有点离谱:GPT-5-nano 会把每封邮件丢进三个桶里的一个。归档、阅读或者回复。就这么简单。
整套东西都跑在 n8n 上,因为我用的是 OpenAI 最便宜、又支持结构化输出的模型,所以成本几乎可以忽略不计。没错,现在 OpenAI 能看到我所有个人邮件了,但说实话,他们大概早就从我在 ChatGPT 里的对话里知道更多了。
这不是什么我拿出来兜售的理论概念。我已经把它在线上环境跑了三个月,而且它每周都在给我省下好几个小时。
我为什么做这套邮件自动化系统
我收到的邮件实在太多了。新闻订阅、服务通知、真人发来的重要消息,全都落在同一个收件箱里。Gmail 自带的分类总是漏掉一些很明显的模式,而我每天早上都要花 20 分钟,仅仅是决定哪些邮件值得读。
真正让我受不了的时刻,是我意识到自己有 80% 的邮件其实都没看,直接就归档了。如果大多数邮件根本不需要我注意,那为什么还得由我来决定哪些需要?
更喜欢视频教程? 我录了一个完整的分步骤演示,把这套邮件自动化工作流从头到尾走了一遍。查看用 n8n 和 LLM 做邮件自动化的教程,可以直接看到完整配置过程。

真正有效的三分类系统
我的 AI 会把每一封邮件严格分成三类:
- 归档 - 我订阅了但基本不看的新闻邮件、自动通知、促销邮件
- 阅读 - 我想看,但不需要回复的内容
- 回复 - 需要我亲自回复的邮件
不需要复杂的文件夹结构,也不需要优先级体系。就三个简单动作,覆盖我 100% 的邮件。
搭建 n8n 工作流
下面就是能把这一切自动跑起来的完整 n8n 工作流:
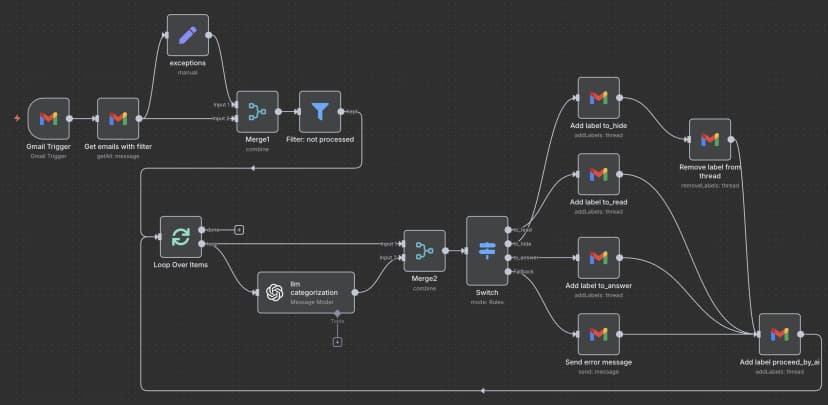
每当 Gmail 收件箱里进来新邮件,这个工作流就会触发。它会抓取邮件内容,发给 OpenAI 做分类,然后在 Gmail 里打上对应标签,把那些不需要我关注的邮件直接归档。
需要的 n8n 节点
你的工作流里需要这些节点:
- Gmail Trigger - 监控新邮件
- OpenAI Chat Model - 分类邮件内容
- Gmail - 添加标签并归档邮件
- IF conditions - 根据 AI 的判断把邮件路由到不同分支
真正的关键在 OpenAI 节点的配置上。下面是我的设置方式:
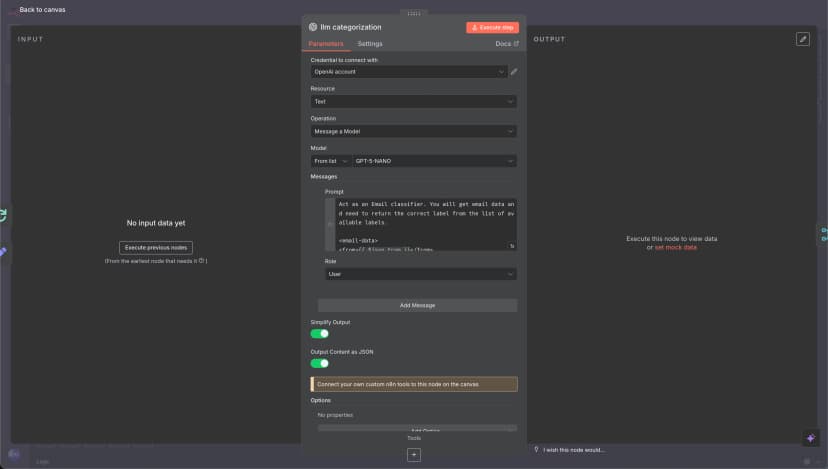
真正让它跑起来的 LLM Prompt
Prompt 是这套系统的核心。试了几十种变体之后,这一版给我的结果最稳定:
说明:下面只是邮件分类用的 LLM prompt。如果你想看完整的 n8n 自动化工作流(包括所有节点和连线),请直接往下滚到“完整 n8n Workflow JSON”那一节。
点击展开完整 LLM prompt
Act as an Email classifier. You will get email data and need to return the correct label from the list of available labels.
<email-data>
<from>{{ $json.From }}</from>
<to>{{ $json.To }}</to>
<email-subject>
{{ $json.Subject }}
</email-subject>
<email-snippet>
{{ $json.snippet }}
</email-snippet>
</email-data>
<possible-labels>
<to_read>
- `to_read` — for emails that need to be read by a human.
<to_read-examples>
- a secret code from the app/service
- notification about a message in another system, Kirill needs to log in and answer
- notification about something important Kirill needs to do
- notification from GitHub about a new message or issue in my project
</to_read-examples>
</to_read>
<to_hide>
- `to_hide` — for emails that are OK to be in the archive, but not needed to be read by a human right now.
<to_hide-examples>
- Invoices
- Some subscription for charity or news
- Product updates
- Advertising
- Proposals from companies without a history of our communications, but do not hide proposals from individuals
- Mentioning me in Discord or Slack (most likely spam and group mentions, or I will see it again in Slack, and no need to see here)
- Slack notification about new messages because Kirill will see them in Slack, no need to see them in email.
- Community summaries
- Some service incidents are mentioned, and an overview
- Notification about one more subscriber, because it does not need action from Kirill, and we can hide it.
- meeting notes from some AI software, because it is OK to have them in the archive, but Kirill doesn't need to reread them now.
</to_hide-examples>
</to_hide>
<to_answer>
- `to_answer` — for emails that need an answer.
<to_answer-examples>
- some emails with questions from a person or a company
</to_answer-examples>
<to_answer-bad-examples>
- message in external system, not in Gmail — bad example because Kirill can not answer via email. We need to mark these emails as to_read.
</to_answer-bad-examples>
</to_answer>
</possible-labels>
{{$node["exceptions"].json["additional-data-for-classify"]}}
Answer in JSON with two fields:
- `reasoning`
- `label`
我用结构化输出,确保 AI 始终返回合法类别。这样就没有解析错误,也不会出现模型突然用奇怪格式作答的边角情况。
三个月真实使用结果
自从我把这套系统跑起来之后:
- 节省时间:每天大约省下 15 到 20 分钟的邮件分拣时间
- 准确率:AI 对邮件的分类准确率大约在 95%
- 成本:使用 GPT-5-nano 时每月不到 3 美元
- 误判:大概每周只有 2 到 3 封邮件会被分错
5% 的误差完全可以接受。AI 分错的时候,我只要把邮件移到正确类别就行,整体还是比手动分拣快得多。
安全性考虑(以及我为什么能接受)
是的,OpenAI 现在会处理我所有个人邮件。从隐私角度看,这当然不完美,但我最终还是接受了,原因主要有几个。
第一,我早就用密码管理器和不依赖邮件的 2FA 验证码,所以即便邮箱本身出问题,也不至于灾难性。第二,OpenAI 通过我平时用 ChatGPT,原本就已经知道不少关于我的事。第三,对我这种个人工作流来说,节省下来的时间值得这笔隐私交换。
如果你处理的是敏感的商业邮件,那你可能更适合用本地 LLM,而不是 OpenAI API。n8n 这套搭法本身不变。
怎么开始搭你自己的邮件自动化
你可以这样自己搭这套系统:
- 搭好 n8n - 自托管也行,用 n8n Cloud 也行
- 连接 Gmail - 你需要完成 Gmail 账号授权
- 获取 OpenAI API 访问权限 - 注册账号并拿到 API key
- 导入工作流 - 如果有人需要,我会分享 JSON 导出文件
- 定制 prompt - 按照你的邮件模式调整分类逻辑
- 先拿少量邮件测试 - 在全面自动化之前先小规模验证
如果你已经熟悉 n8n,整个配置大概 30 分钟就够。要是从零开始,可能需要一个小时左右。
为什么这比 Gmail 自带功能更好
Gmail 的自动分类是为所有人设计的,也就意味着它不会为任何一个具体的人做到真正优化。我的系统学的是我自己的邮件模式和偏好。
而且我随时都能改逻辑。想加第四个类别?改 prompt。需要对某些发件人特殊处理?加一个条件节点。Gmail 的规则很僵硬,而这套系统可以跟着我的需求一起变。
结论
跑了三个月之后,这套邮件自动化系统已经成了我日常工作流里不可缺少的一部分。它并不完美,但和每周手动整理几百封邮件相比,已经好太多了。
配置不复杂,持续成本很低,节省时间也是真实的。如果你也像我之前一样被邮件淹没,这个方法值得试试看。
只要记住一点:先从简单开始,充分测试,不要自动化任何你没法轻松撤销的东西。
完整 n8n Workflow JSON
如果你已经准备好亲手实现这套系统,下面就是可以直接导入的完整 n8n 工作流:
点击展开完整 JSON 工作流
{
"name": "email-ai-automation-personal",
"nodes": [
{
"parameters": {
"rules": {
"values": [
{
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"leftValue": "={{ $json.message.content.label }}",
"rightValue": "to_read",
"operator": {
"type": "string",
"operation": "equals"
},
"id": "585b8b65-2369-4f4e-ba0d-4a7dfc7cdef9"
}
],
"combinator": "and"
},
"renameOutput": true,
"outputKey": "to_read"
},
{
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "99e46836-ea2f-41d7-8ebc-24bd5cfadd41",
"leftValue": "={{ $json.message.content.label }}",
"rightValue": "to_hide",
"operator": {
"type": "string",
"operation": "equals",
"name": "filter.operator.equals"
}
}
],
"combinator": "and"
},
"renameOutput": true,
"outputKey": "to_hide"
},
{
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "2a10fb26-99e6-43ab-854c-2d208f701ac3",
"leftValue": "={{ $json.message.content.label }}",
"rightValue": "to_answer",
"operator": {
"type": "string",
"operation": "equals",
"name": "filter.operator.equals"
}
}
],
"combinator": "and"
},
"renameOutput": true,
"outputKey": "to_answer"
}
]
},
"options": {
"fallbackOutput": "extra"
}
},
"type": "n8n-nodes-base.switch",
"typeVersion": 3.2,
"position": [
-1552,
432
],
"id": "ff266540-edd6-42ef-8e07-f1754c1aa394",
"name": "Switch"
},
{
"parameters": {
"options": {}
},
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
-2256,
432
],
"id": "66a72457-b0e5-4ab0-bf49-ef00a06213aa",
"name": "Loop Over Items"
},
{
"parameters": {
"resource": "thread",
"operation": "addLabels",
"threadId": "={{ $json.threadId }}",
"labelIds": []
},
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"position": [
-1296,
112
],
"id": "47db305c-2f55-4797-b646-331903a798ad",
"name": "Add label to_hide",
"webhookId": "",
"credentials": {}
},
{
"parameters": {
"resource": "thread",
"operation": "addLabels",
"threadId": "={{ $json.threadId }}",
"labelIds": []
},
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"position": [
-1296,
480
],
"id": "bb1c5387-99a2-42ba-b615-ae65f39e9337",
"name": "Add label to_answer",
"webhookId": "",
"credentials": {}
},
{
"parameters": {
"resource": "thread",
"operation": "addLabels",
"threadId": "={{ $json.threadId }}",
"labelIds": []
},
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"position": [
-1296,
288
],
"id": "82f68387-c342-4222-87c3-f6bbb1a23f77",
"name": "Add label to_read",
"webhookId": "",
"credentials": {}
},
{
"parameters": {
"resource": "thread",
"operation": "addLabels",
"threadId": "={{ $('Merge2').item.json.threadId }}",
"labelIds": []
},
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"position": [
-880,
656
],
"id": "7de8f655-3c3d-49f9-9074-b39eaf4abaf2",
"name": "Add label processed_by_ai",
"webhookId": "",
"credentials": {}
},
{
"parameters": {
"resource": "thread",
"operation": "removeLabels",
"threadId": "={{ $('Merge2').item.json.threadId }}",
"labelIds": [
"INBOX"
]
},
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"position": [
-1040,
208
],
"id": "438c1618-edf3-41a1-b991-fef18b003edf",
"name": "Remove label from thread",
"webhookId": "",
"credentials": {}
},
{
"parameters": {
"pollTimes": {
"item": [
{
"mode": "everyX"
}
]
},
"filters": {}
},
"type": "n8n-nodes-base.gmailTrigger",
"typeVersion": 1.2,
"position": [
-2560,
160
],
"id": "676e065d-fc0b-4ae4-8c1b-4b663267023f",
"name": "Gmail Trigger",
"credentials": {}
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "be8e84b9-48af-4a49-b4f7-797382c13afe",
"name": "additional-data-for-classify",
"value": "<additional-data-for-classify>\n- All messages from Deel with the main idea, like `New contractor submission`, please mark as `to_hide`.\n</additional-data-for-classify>",
"type": "string"
}
]
},
"options": {}
},
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-2240,
-32
],
"id": "9cb4e14e-cd43-4a7b-96c9-7acd93b8b947",
"name": "exceptions"
},
{
"parameters": {
"modelId": {
"__rl": true,
"value": "gpt-5-mini",
"mode": "list",
"cachedResultName": "GPT-5-MINI"
},
"messages": {
"values": [
{
"content": "=Act as an Email classifier. You will get email data and need to return the correct label from the list of available labels.\n\n<email-data>\n<from>{{ $json.From }}</from>\n<to>{{ $json.To }}</to>\n<email-subject>\n{{ $json.Subject }}\n</email-subject>\n<email-snippet>\n{{ $json.snippet }}\n</email-snippet>\n</email-data>\n\n<possible-lables>\n\n<to_read>\n- `to_read` — for emails that need to be read by a human. \n<to_read-examples>\n- a secret code from the app/service\n- notification about a message in another system, Kirill needs to log in and answer\n- notification about something important Kirill needs to do\n- notification from GitHub about a new message or issue in my project\n</to_read-examples>\n</to_read>\n\n<to_hide>\n- `to_hide` — for emails that are OK to be in the archive, but not needed to be read by a human right now. \n<to_hide-examples> \n- Invoices \n- Some subscription for charity or news\n- Product uddates\n- Advertising\n- Proposals from companies without a history of our communications, but do not hide proposals from individuals\n- Mentioning me in Discord or Slack (most likely spam and group mentions, or I will see it again in Slack, and no need to see here)\n- Slack notification about new messages because Kirill will see them in Slack, no need to see them in email.\n- Community summaries\n- Some service incidents are mentioned, and an overview\n- Notification about one more subscriber, because it does not need action from Kirill, and we can hide it.\n- meeting notes from some AI software, because it is OK to have them in the archive, but Kirill doesn't need to reread them now.\n</to_hide-examples>\n</to_hide>\n\n<to_answer>\n- `to_answer` — for emails that need an answer.\n<to_answer-examples>\n- some emails with questions from a person or a company\n</to_answer-examples>\n<to_answer-bad-examples>\n- message in external system, not in Gmail — bad example because Kirill can not answer via email. We need to mark these emails as to_read.\n</to_answer-bad-examples>\n</to_answer>\n\n</possible-lables>\n\n{{$node[\"exceptions\"].json[\"additional-data-for-classify\"]}}\n\nAnswer in JSON with two fields:\n- `reasoning`\n- `label`"
}
]
},
"jsonOutput": true,
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.openAi",
"typeVersion": 1.8,
"position": [
-2032,
560
],
"id": "4f65ce04-67eb-4c28-9d56-6d2f03dedd41",
"name": "llm categorization",
"alwaysOutputData": false,
"credentials": {}
},
{
"parameters": {
"conditions": {
"options": {
"caseSensitive": true,
"leftValue": "",
"typeValidation": "strict",
"version": 2
},
"conditions": [
{
"id": "95f8838a-df88-496c-a0ea-d19c612eb81b",
"leftValue": "={{ $json.labels.filter(item => item.id == \"__REPLACE_WITH_YOUR_PROCESSED_LABEL_ID__\") }}",
"rightValue": "={{ \"\" }}",
"operator": {
"type": "array",
"operation": "empty",
"singleValue": true
}
}
],
"combinator": "and"
},
"options": {}
},
"type": "n8n-nodes-base.filter",
"typeVersion": 2.2,
"position": [
-1936,
144
],
"id": "cc8dda5a-414c-4fb8-9774-6bdfe1224976",
"name": "Filter: not processed"
},
{
"parameters": {
"sendTo": "",
"subject": "There is a problem with AI email workflow — AI choose the wrong option",
"emailType": "text",
"message": "!",
"options": {}
},
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"position": [
-1296,
656
],
"id": "90cfc5e9-cddd-418e-bf95-5e9eb77b6778",
"name": "Send error message",
"webhookId": "",
"credentials": {}
},
{
"parameters": {
"operation": "getAll",
"returnAll": true,
"filters": {
"q": "=label:INBOX -label:__REPLACE_WITH_YOUR_PROCESSED_LABEL_ID__ after:2025/06/15"
}
},
"type": "n8n-nodes-base.gmail",
"typeVersion": 2.1,
"position": [
-2400,
160
],
"id": "5d534d0c-0210-4d32-853d-d26a5b13c646",
"name": "Get emails with filter",
"webhookId": "",
"credentials": {}
},
{
"parameters": {
"mode": "combine",
"combineBy": "combineByPosition",
"options": {}
},
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2,
"position": [
-2080,
144
],
"id": "c6e6b5bd-0196-4a4f-a36d-1f119df3ee5d",
"name": "Merge1"
},
{
"parameters": {
"mode": "combine",
"combineBy": "combineByPosition",
"options": {}
},
"type": "n8n-nodes-base.merge",
"typeVersion": 3.2,
"position": [
-1696,
464
],
"id": "d109e9f9-1089-4060-89e4-e70762d0aea5",
"name": "Merge2"
}
],
"pinData": {},
"connections": {
"Switch": {
"main": [
[
{
"node": "Add label to_read",
"type": "main",
"index": 0
}
],
[
{
"node": "Add label to_hide",
"type": "main",
"index": 0
}
],
[
{
"node": "Add label to_answer",
"type": "main",
"index": 0
}
],
[
{
"node": "Send error message",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[],
[
{
"node": "llm categorization",
"type": "main",
"index": 0
},
{
"node": "Merge2",
"type": "main",
"index": 0
}
]
]
},
"Add label to_hide": {
"main": [
[
{
"node": "Remove label from thread",
"type": "main",
"index": 0
}
]
]
},
"Add label to_answer": {
"main": [
[
{
"node": "Add label processed_by_ai",
"type": "main",
"index": 0
}
]
]
},
"Add label to_read": {
"main": [
[
{
"node": "Add label processed_by_ai",
"type": "main",
"index": 0
}
]
]
},
"Add label processed_by_ai": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Remove label from thread": {
"main": [
[
{
"node": "Add label processed_by_ai",
"type": "main",
"index": 0
}
]
]
},
"Gmail Trigger": {
"main": [
[
{
"node": "Get emails with filter",
"type": "main",
"index": 0
}
]
]
},
"exceptions": {
"main": [
[
{
"node": "Merge1",
"type": "main",
"index": 0
}
]
]
},
"llm categorization": {
"main": [
[
{
"node": "Merge2",
"type": "main",
"index": 1
}
]
]
},
"Filter: not processed": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Send error message": {
"main": [
[
{
"node": "Add label processed_by_ai",
"type": "main",
"index": 0
}
]
]
},
"Get emails with filter": {
"main": [
[
{
"node": "exceptions",
"type": "main",
"index": 0
},
{
"node": "Merge1",
"type": "main",
"index": 1
}
]
]
},
"Merge1": {
"main": [
[
{
"node": "Filter: not processed",
"type": "main",
"index": 0
}
]
]
},
"Merge2": {
"main": [
[
{
"node": "Switch",
"type": "main",
"index": 0
}
]
]
}
},
"active": true,
"settings": {
"executionOrder": "v1",
"callerPolicy": "workflowsFromSameOwner"
},
"versionId": "",
"meta": {
"templateCredsSetupCompleted": true,
"instanceId": ""
},
"id": "",
"tags": []
}
导入说明
- 复制上面的 JSON
- 将它保存为名为
email-ai-automation-personal.json的文件 - 在 n8n 里进入 Workflows → Import from JSON
- 选择你保存的文件,然后点击 Import
- 配置 Gmail 和 OpenAI 的凭据
- 把
__REPLACE_WITH_YOUR_PROCESSED_LABEL_ID__替换成你要给已处理邮件使用的标签 ID - 配置出错时发送的邮件(fallback)
- 在启用触发器之前,先用几封邮件测试
导入之后,记得更新 OpenAI API key 和 Gmail 认证信息。
视频教程:看完整配置过程
如果你更喜欢视频学习,我也录了一个完整教程,把这套邮件自动化系统的搭建过程全部走了一遍:
视频会展示创建 n8n 工作流、配置 OpenAI 集成、连接 Gmail,以及测试整个自动化流程的每一步。你会看到节点的精确配置、LLM prompt 的实际效果,以及系统如何实时分类真实邮件。