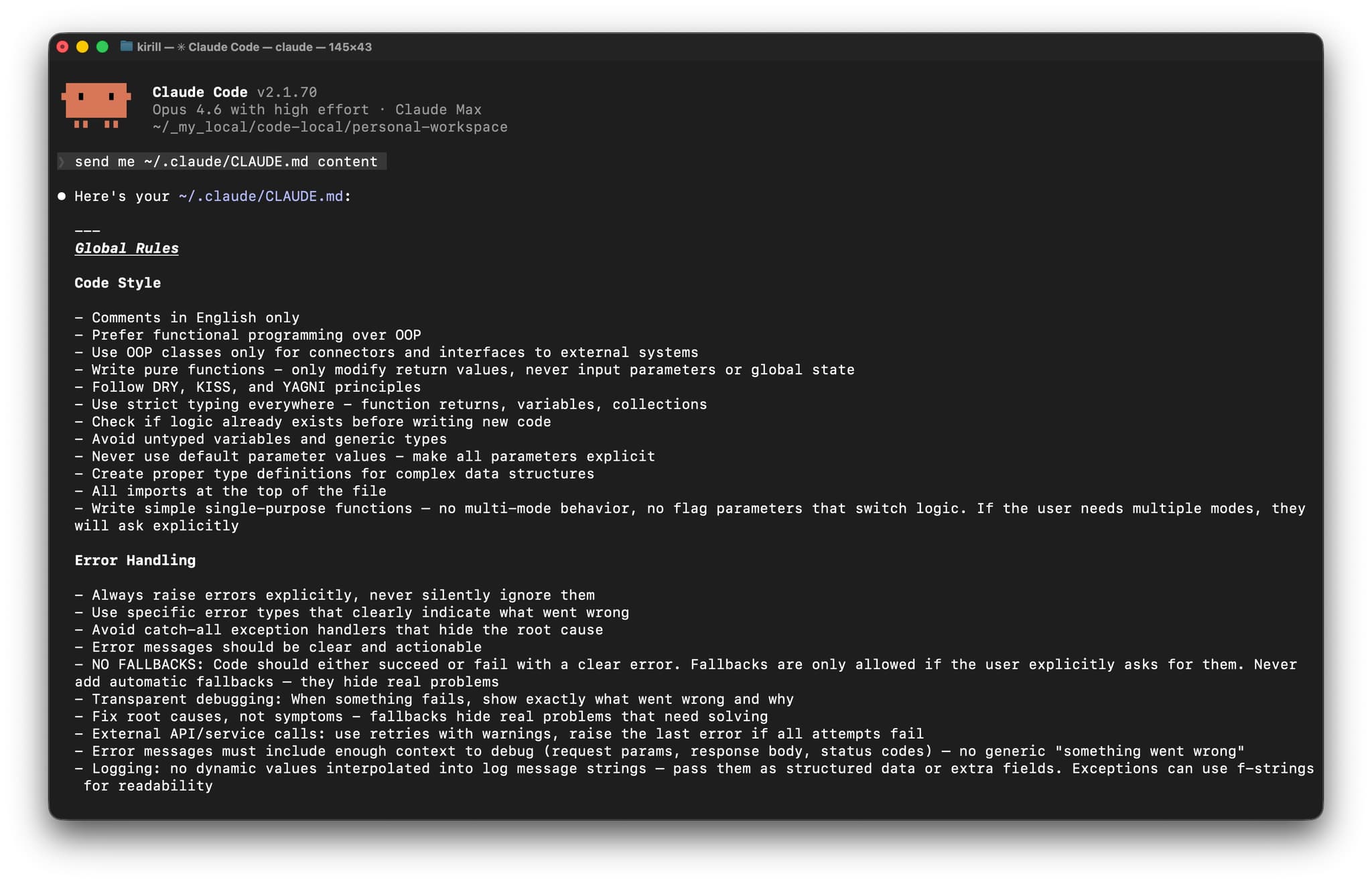
问题:LLM 和 Jupyter Notebook 天生有点别扭
那天凌晨两点,我终于承认自己卡住了。我的基因测序分析停在半路,因为 Cursor IDE 里的 LLM 助手始终没法稳定处理 Jupyter Notebook 那套复杂的 JSON 结构。每次让 AI 帮我改可视化代码,最后得到的都是损坏的 JSON,连笔记本都打不开。我也试过只贴几段代码片段,但这样又丢掉了前面数据预处理的上下文。与此同时,我桌面上还开着三个窗口:浏览器里的 Jupyter、用来认真写代码的 VSCode,以及另一个专门写文档的编辑器。Jupyter 的文件格式、LLM 的局限,再加上不停切换上下文,让复杂的数据分析很难顺畅推进。即便只是 Iris 这种更简单的示例数据集,这种根本性的错位也一直在吞掉我的效率。
如果你也做过数据分析,这种感觉应该不陌生。数据科学工作流最折磨人的地方之一,就是你总得在这些工具之间来回跳:
- 写代码的编辑器
- 做探索分析的 Jupyter Notebook
- 用来整理结论的文档工具
- 专门制作图表的可视化软件
- 浏览器里开着的 ChatGPT 和 Claude
每切换一次,都会消耗一点注意力,也会让整个分析过程多一层阻力。但如果有一种方式,能把这些环节尽量合到一起呢?
更喜欢视频教程? 我录了一份完整的分步演示。观看在 Cursor IDE 中使用 Jupyter Notebook 与 AI 做数据分析的视频教程,可以直接看到整套流程是怎么跑起来的。
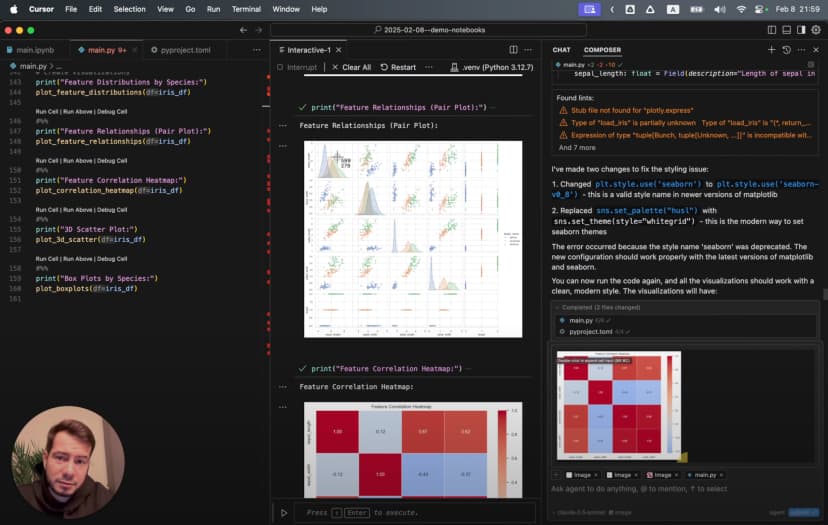
发现:把 Jupyter、IDE 和 LLM 放进同一套工作流
后来我找到了一种彻底改变工作方式的办法:直接在 Cursor IDE 里使用 Jupyter Notebook,再把 AI 能力叠加上去。这种做法把几个关键优势放到了同一个环境里:
- Jupyter 按单元交互执行的体验
- IDE 才有的编辑、搜索和导航能力
- 能理解代码和数据分析任务的 AI 辅助
- 更适合版本控制的纯文本文件格式
读完这篇文章,你会看到我是怎么搭出一个一体化环境,让自己能够:
- 用更少的手写代码完成数据分析和可视化
- 创建能帮助发现隐藏模式的 3D 可视化
- 在代码旁边直接记录分析过程和结论
- 用一条命令导出专业级报告
- 尽量不在不同工具之间来回切换
如果你也受够了这种被工具打断的感觉,我们就从这里开始。
在 Cursor IDE 中搭建 Jupyter 环境:先把基础打好
顺手的工作流,前提都是环境先搭对。要在 Cursor IDE 里用好 Jupyter,先把工具装齐,再把 Python 环境整理清楚。
安装 Jupyter 扩展
整套流程的起点,是 Cursor IDE 的 Jupyter 扩展:
- 打开 Cursor IDE,创建一个项目目录
- 在侧边栏进入
Extensions - 搜索
Jupyter,找到官方扩展 - 点击
Install
这个扩展相当于传统 Notebook 和 IDE 之间的桥梁。它带来的关键能力是:你可以在普通 Python 文件里,用特殊标记创建可执行单元。这样就不必再依赖结构复杂的 .ipynb 文件,而是可以直接用纯文本 Python 文件完成整套 Notebook 工作流。
如果你想进一步了解 Jupyter Notebook 的能力,可以查看 Jupyter Notebook 官方文档。
准备 Python 环境
扩展装好以后,接着准备一个规范的 Python 环境:
python -m venv .venv
然后创建一个 pyproject.toml 文件来管理依赖:
[build-system]
requires = ["setuptools>=42.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "jupyter-cursor-project"
version = "0.1.0"
description = "Data analysis with Jupyter in Cursor IDE"
[tool.poetry.dependencies]
python = "^3.9"
jupyter = "^1.0.0"
pandas = "^2.1.0"
numpy = "^1.25.0"
matplotlib = "^3.8.0"
seaborn = "^0.13.0"
scikit-learn = "^1.2.0"
接着在虚拟环境里安装这些依赖:
pip install -e .
我是在踩过坑之后才意识到,版本冲突很容易引发一些看起来莫名其妙的错误。只要 AI 生成的代码要导入某个库,最好先确认它确实已经安装在当前环境里。
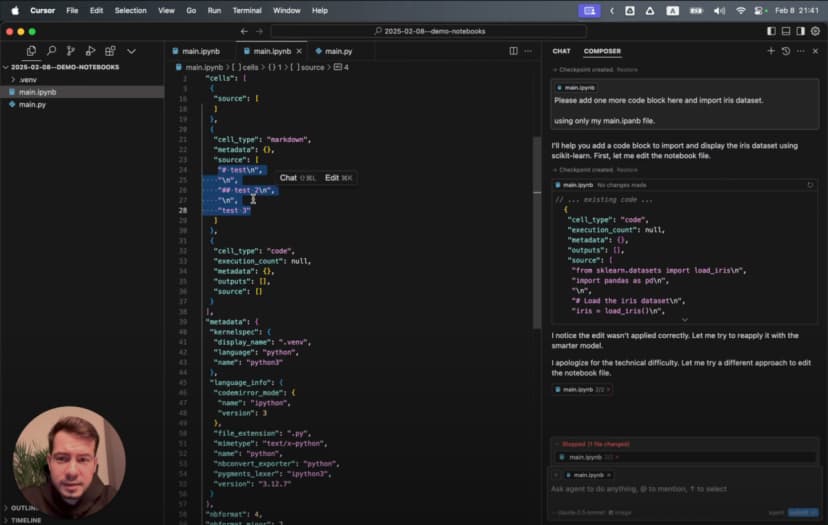
创建你的第一个 Notebook:纯文本方式的优势
传统 Jupyter Notebook 使用 .ipynb 格式,本质上是一套复杂的 JSON 结构。这个格式既不适合直接编辑,也几乎不可能让 AI 在不破坏结构的前提下稳定修改。相比之下,纯文本方式能把两边的优点结合起来。
原生 Jupyter Notebook 的问题
下面是一个传统 .ipynb 文件在文本编辑器里打开时的样子:
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# My Notebook Title\n",
"This is a markdown cell with text."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": ["Hello, world!"]
}
],
"source": [
"print(\"Hello, world!\")"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
这种结构对 Cursor 所用的 LLM 来说尤其麻烦,主要有几个原因:
- JSON 里有大量和实际内容无关的符号与嵌套结构
- 每个单元的内容都被存成字符串数组,还带着换行和引号转义
- 代码和输出分散在结构的不同位置
- 哪怕只改一小处,也得理解整个 JSON schema 才不至于把文件弄坏
- 内容稍微变动一下,JSON diff 就会变得很大,AI 很难精确地产生修改
当 LLM 尝试修改这种格式时,往往很难一边维持 JSON 结构正确,一边完成有意义的内容更新。结果就是笔记本损坏,既打不开,也无法运行。
单元标记的关键作用
创建一个名为 main.py 的文件,先加入第一个单元:
# %%
# 导入所需库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置显示选项,便于观察数据
pd.set_option('display.max_columns', None)
plt.style.use('ggplot')
print("数据分析环境已就绪!")
看到顶部的 # %% 了吗?这就是关键标记。Jupyter 扩展会把它识别为一个代码单元。加上这个标记后,你会看到旁边出现运行按钮;只执行这一段,结果就会直接显示在编辑器里。
再添加一个说明单元:
# %% [markdown]
"""
# Iris 数据集分析
这个笔记本会探索经典的 Iris 鸢尾花数据集,重点回答以下问题:
- 不同花朵测量特征之间有什么关系
- 这些特征能否区分不同物种
- 哪些特征最能把不同物种区分开来
数据集中的每一朵花都属于以下三种物种之一:
1. Setosa
2. Versicolor
3. Virginica
"""
这是一种很实用的组合:可执行代码和完整文档共存在同一个纯文本文件里。没有额外文件格式,也没有浏览器编辑的限制,版本控制也更顺手。
在逐步搭建这个 Notebook 时,我们会遵循下面的结构:
- 用
# %%表示代码单元 - 用
# %% [markdown]加三引号编写说明文本 - 按照“载入数据、探索数据、可视化数据”的逻辑推进
- 一边分析,一边把过程和发现记录下来
让 LLM 真正帮上忙:把它当成数据分析助手
真正让这套工作流有价值的,是它和 Cursor Composer 的整合。它不只是自动补全,而更像一个能理解数据分析语境的协作助手。
Agent 模式:让 LLM 真正参与数据分析
在 Cursor IDE 中点击 Composer,然后切换到 Agent 模式。这样会启用一个更完整的 AI 助手,它能够:
- 在多轮交互中保留上下文
- 理解你的数据集和分析目标
- 生成带有正确 Jupyter 语法的完整代码单元
- 根据你的数据生成合适的可视化
先让它帮我们导入一个数据集:
请按这种笔记本格式导入 Iris 数据集
AI 会生成一个完整、可执行的单元:
# %%
# 导入所需库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# 载入 Iris 数据集
iris = load_iris()
# 转换为 pandas DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['species'] = iris.target
# 查看前几行
print(df.head())
只用一句简单提示词,我们就得到一个格式正确、可直接运行的代码单元。函数名、导入方式和整体结构都不需要再自己硬记,AI 会先帮你搭好。
但真正能看出效果的,是让它直接生成可视化:
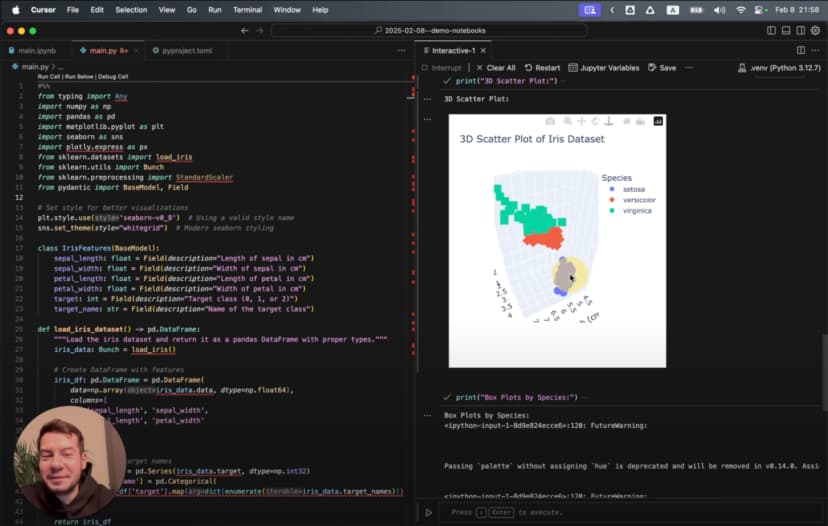
请为 Iris 数据集生成一个三维散点图,用不同颜色表示三种物种
AI 会创建一个带有旋转效果的复杂 3D 可视化:
# %%
# 创建 3D 散点图
from mpl_toolkits.mplot3d import Axes3D
# 创建图形和 3D 坐标轴
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 获取三种物种名称
species_names = iris.target_names
colors = ['blue', 'red', 'green']
# 为每个物种使用不同颜色绘图
for species_id, species_name in enumerate(species_names):
# 筛选当前物种的数据
species_data = df[df['species'] == species_id]
# 绘制当前物种
ax.scatter(
species_data['sepal length (cm)'],
species_data['sepal width (cm)'],
species_data['petal length (cm)'],
c=colors[species_id],
label=species_name,
s=60,
alpha=0.8
)
# 设置标签和标题
ax.set_xlabel('Sepal Length (cm)')
ax.set_ylabel('Sepal Width (cm)')
ax.set_zlabel('Petal Length (cm)')
ax.set_title('3D Scatter Plot of Iris Dataset')
ax.legend()
# 添加旋转效果,便于观察
for angle in range(0, 360, 5):
ax.view_init(30, angle)
plt.draw()
plt.pause(0.001)
plt.show()
这已经不只是“画一张图”了,而是一张会旋转、能从多个角度观察数据的 3D 可视化,标签、颜色和格式也都处理妥当,而且只来自一句提示词。
用 Cursor 规则引导 LLM 生成更贴合习惯的代码
我后来发现,还可以在项目根目录创建一个 .cursorrules 文件,让 AI 生成的代码更贴近自己的习惯。这个文件里放的是自定义说明,用来约束 AI 该如何写代码。
如果你想系统了解如何配置和使用 Cursor 规则,可以参考我另一篇更详细的文章:如何用 Cursor 规则优化 AI 编码体验。
例如,我加入了这些规则:
<cursorrules_code_style>
- Prefer functional programming over OOP
- Use pure functions with clear input/output
- Use strict typing for all variables and functions
</cursorrules_code_style>
<cursorrules_python_specifics>
- Prefer Pydantic over TypedDict for data models
- Use pyproject.toml over requirements.txt
- For complex structures, avoid generic collections
</cursorrules_python_specifics>
加上这些规则后,AI 开始稳定生成符合我偏好的类型安全代码:
# %%
# 定义 Pydantic 模型,增强类型安全
from pydantic import BaseModel
from typing import List, Optional
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
species: int
species_name: Optional[str] = None
# 将 DataFrame 行转换为 Pydantic 模型
def convert_to_models(df: pd.DataFrame) -> List[IrisFeatures]:
species_map = {0: "setosa", 1: "versicolor", 2: "virginica"}
return [
IrisFeatures(
sepal_length=row["sepal length (cm)"],
sepal_width=row["sepal width (cm)"],
petal_length=row["petal length (cm)"],
petal_width=row["petal width (cm)"],
species=row["species"],
species_name=species_map[row["species"]]
)
for _, row in df.iterrows()
]
# 转换一个样本做演示
iris_models = convert_to_models(df.head())
for model in iris_models:
print(model)
AI 基本会按这些规则来生成代码,产出的结果类型更明确,也更接近我平时偏好的函数式写法和数据模型风格。
用 Python 探索 Iris 数据集:开始真正做分析
环境已经搭好,AI 助手也准备就绪,现在可以正式开始探索经典的 Iris 数据集了。
先看一眼数据
数据已经载入,但我们先看看它的整体结构:
# %%
# 获取数据集的基础信息
print("Dataset shape:", df.shape)
print("\nClass distribution:")
print(df['species'].value_counts())
# 创建一个更易读的物种名称列
species_names = {0: 'setosa', 1: 'versicolor', 2: 'virginica'}
df['species_name'] = df['species'].map(species_names)
# 显示描述性统计
print("\nDescriptive statistics:")
print(df.describe())
从这里可以看出,我们有 150 个样本,每个物种各 50 个,一共 4 个描述花朵不同部位的特征。接着,再用箱线图看看这些特征在不同物种之间是怎么变化的:
# %%
# 为每个特征按物种绘制箱线图
plt.figure(figsize=(12, 10))
for i, feature in enumerate(iris.feature_names):
plt.subplot(2, 2, i+1)
sns.boxplot(x='species_name', y=feature, data=df)
plt.title(f'Distribution of {feature} by Species')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
这些箱线图会揭示一些很直观的模式。Setosa 的花萼明显更宽,但花瓣较小;Virginica 的花瓣整体最大。不过,究竟哪些特征最能把不同物种区分开?
找出隐藏模式
为了回答这个问题,我们需要看特征之间的关系:
# %%
# 绘制 pairplot,查看特征之间的关系
sns.pairplot(df, hue='species_name', height=2.5)
plt.suptitle('Iris Dataset Pairwise Relationships', y=1.02)
plt.show()
这个 pairplot 很有启发性。它把所有特征的两两组合都画了出来,并按照物种着色。我们几乎可以立刻看出:
- 只要图里包含花瓣测量值,Setosa(蓝色)就会和另外两种完全分开
- Versicolor 和 Virginica 有一定重叠,但仍然可以区分
- 花瓣长度和花瓣宽度最能清楚地区分三种物种
但最醒目的图,还是前面那个 3D 散点图。随着图像旋转到不同角度,会出现几个视角,让三种物种的聚类几乎完全分离,这种洞察在静态二维图里很难直接看出来。
如果你想进一步学习更高级的可视化和数据分析技巧,可以参考内容很扎实的 scikit-learn User Guide。
解决 Jupyter 集成中的障碍:排查依赖问题
再顺的工作流,也总会遇到问题。等我开始尝试更复杂的可视化时,就碰到了一次 Seaborn 导入错误:
ImportError: Seaborn not valid package style
这类问题在数据分析环境里很常见,本质上通常是包版本不兼容。为了定位问题,我加了一个单元来检查当前安装的版本:
# %%
# 检查已安装依赖的版本
import pkg_resources
print("Installed packages:")
for package in ['numpy', 'pandas', 'matplotlib', 'seaborn', 'scikit-learn']:
try:
version = pkg_resources.get_distribution(package).version
print(f"{package}: {version}")
except pkg_resources.DistributionNotFound:
print(f"{package}: Not installed")
最后我发现,是 Seaborn 的版本和 NumPy 版本不兼容。解决办法是利用 Cursor 的弹出终端功能:
- 点击底部面板里的终端图标
- 选择
Pop out terminal - 运行更新命令:
pip install seaborn --upgrade
这正是 Cursor IDE 发挥优势的地方。我不需要切换工具,也不用离开当前分析上下文,就能把依赖问题修好。
更进一步说,我还可以直接把错误信息发给 AI,它会建议出准确的修复命令。弹出终端配合 AI 辅助,排障会比传统环境快很多。
让数据可视化真正帮助理解模式:在 Jupyter 中制作交互图表
环境顺起来之后,我想做的不只是“把图画出来”,而是让图真正帮助我理解数据里的模式。
从简单图表到 3D 可视化
我先从一个关注花瓣尺寸的简单散点图开始:
# %%
# 绘制花瓣尺寸散点图
plt.figure(figsize=(10, 6))
for species_id, species_name in enumerate(iris.target_names):
species_data = df[df['species'] == species_id]
plt.scatter(
species_data['petal length (cm)'],
species_data['petal width (cm)'],
label=species_name,
alpha=0.7,
s=70
)
plt.title('Petal Dimensions by Species')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
这个图会立刻显示出,Setosa 在左下角形成了一个很紧的簇,花瓣测量值和另外两种物种明显不同。
为了更深入理解这些关系,我又做了一个相关性热力图:
# %%
# 计算相关系数矩阵
correlation_matrix = df.drop(columns=['species_name']).corr()
# 绘制热力图
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation_matrix,
annot=True,
cmap='coolwarm',
linewidths=0.5,
vmin=-1,
vmax=1
)
plt.title('Correlation Matrix of Iris Features')
plt.show()
热力图显示,花瓣长度和花瓣宽度之间存在非常强的相关性,相关系数达到 0.96。换句话说,这两个特征往往会一起变化。
不过,最令人印象深刻的还是前面那个带旋转效果的 3D 散点图。随着视角变化,会出现一些瞬间,让三种物种几乎完全分离,揭示出静态二维图里很难捕捉到的模式。
这就是交互式数据可视化的价值。它能把抽象数字转化为更直观、更容易形成判断的观察结果。
分享分析结果:从探索到展示
在挖出这些洞察之后,我需要把结果分享给那些没有安装 Python 或 Jupyter 的同事。这时,Jupyter 扩展的导出能力就变得非常关键。
制作专业报告
为了生成一份可分享的报告:
- 我先确认所有单元都执行过,保证输出完整可见
- 添加说明单元,解释方法和结论
- 使用 Jupyter 扩展里的
Export as HTML - 在浏览器中打开 HTML 文件,再用
Save as PDF生成更正式的文档
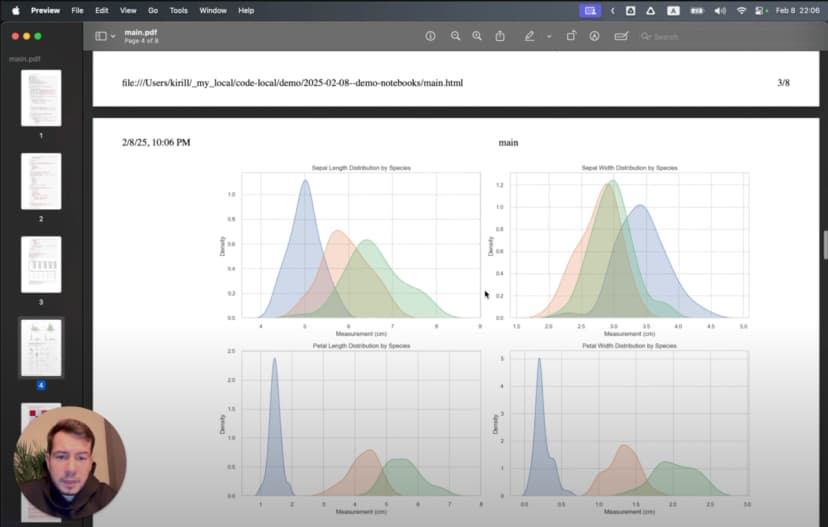
最终得到的报告会包含全部代码、说明文字和可视化内容,而且任何人都可以打开查看。前面在 Markdown 排版上的细心处理也会在这里得到回报,因为标题、项目符号和强调样式都能较好地保留到最终文档中。
如果要把报告展示给非技术背景的受众,我通常会把图表尺寸调到更适合展示的规格,例如:
plt.figure(figsize=(10, 6), dpi=300)
这样可以保证图表在导出的 PDF 里依然清晰、易读。
对于 3D 可视化,我会在导出之前把视角停在最能传达信息的角度,因为旋转动画最终会被导出为一张静态图。只要角度选得好,报告就能准确突出我想强调的模式。
工作流的变化:在 Cursor IDE 中做 LLM 加持的数据分析
回头看整个过程,这种变化很明显。过去需要三套工具、不断切换上下文才能完成的工作,现在可以在一个环境里顺畅做完。我的流程变成了:
- 探索: 用 AI 帮忙载入数据并生成初步可视化
- 发现: 利用 Jupyter 的按单元执行方式交互式细化分析
- 记录: 通过说明单元把结论直接写在代码旁边
- 分享: 用一条命令把完整分析导出为专业报告
Jupyter 的交互性、Cursor IDE 的编辑能力,以及 AI 辅助结合在一起,消除了过去那些不断打断专注的摩擦。我终于可以顺着自己的问题往前追,而不是不停为工具切换付出额外代价。
还有一个意料之外的好处:因为我用的是纯文本文件,而不是原始的 Jupyter Notebook 格式,整个分析流程终于能被 Git 好好管理。我可以清楚看到每个版本到底改了什么,和团队协作时也更不容易陷入合并冲突。
这不只是节省时间而已,它也改变了我做数据分析的方式。没有那些频繁的上下文切换之后,我更容易保持专注,也更容易沿着一个发现继续深入。分析会更完整,文档会更充分,可视化也会更有效。
如果你已经厌倦了为数据分析工作同时维护多个工具,我建议你试试这种一体化方法:在 Cursor IDE 中配置好 Jupyter,用上 AI 助手,亲自体验统一工作流带来的变化。未来某个凌晨两点的你,可能会感谢现在的自己。
对比:传统 Jupyter 与 LLM 增强的 Cursor IDE
下面这张表可以快速总结传统 Jupyter Notebook 方法和 Cursor IDE 中纯文本 Jupyter 工作流之间的关键差异:
| 对比项 | 传统 Jupyter 笔记本 | Cursor IDE + 纯文本 Jupyter |
|---|---|---|
| 文件格式 | 复杂 JSON(.ipynb) | 纯文本 Python(.py) |
| 版本控制 | 困难,diff 大且容易产生合并冲突 | 很好,可直接融入标准 Git 工作流 |
| IDE 能力 | 代码导航与重构能力有限 | 拥有完整 IDE 能力,如搜索、替换与跳转 |
| AI 辅助 | 有限 | LLM 集成更强,并具备上下文感知能力 |
| 单元执行 | 依赖浏览器界面 | 原生 IDE 环境 |
| 上下文切换 | 做复杂编辑时不可避免 | 所有事情都能在一个环境里完成 |
| 性能 | 大型笔记本时可能变慢 | 受益于原生编辑器性能 |
| 调试 | 调试能力有限 | 拥有完整的 IDE 调试工具 |
| 导出选项 | HTML、PDF 等多种格式 | 通过扩展提供同样能力 |
| 协作 | 与版本控制结合时比较困难 | 符合标准代码协作流程 |
| 依赖管理 | 通常分散在单独的环境文件中 | 环境管理可直接整合进项目 |
| 隐藏状态问题 | 乱序执行时很常见 | 因鼓励线性执行而有所减少 |
| Markdown 支持 | 原生支持 | 通过单元标记获得同等能力 |
| 类型检查 | 没有 | 具备完整 IDE 静态分析支持 |
| 扩展生态 | Jupyter 扩展 | IDE 扩展 + Jupyter 扩展 |
这张对比表已经很清楚地说明了,为什么 Cursor IDE 这种做法对认真做数据分析的人更有优势,尤其是在你想利用 AI 能力、又想保持工作流顺畅的时候。
如果你想更深入了解 Jupyter 的架构和能力,可以继续阅读 Project Jupyter Documentation。
视频教程:完整观看 Cursor IDE 中的 Jupyter 工作流
如果你更喜欢通过视频学习,我也制作了一份完整教程,逐步演示本文涉及的所有内容:

视频会完整展示如何在 Cursor IDE 中设置并使用 Jupyter Notebook、AI 集成是如何工作的、如何创建可视化,以及如何导出结果。整个过程都在同一个环境里完成,而这正是这套工作流最有价值的地方。