المشكلة: دفاتر Jupyter ونماذج اللغة الكبيرة لا ينسجمان بسهولة
كانت الساعة قد تجاوزت الثانية صباحًا عندما اعترفت أخيرًا بالهزيمة. كان تحليل التسلسل الجيني الذي أعمل عليه متوقفًا لأن مساعدي المعتمد على نماذج اللغة الكبيرة (LLM) في Cursor IDE لم يتمكن من فهم بنية JSON المعقدة في دفتر Jupyter كما ينبغي. وكل مرة طلبت فيها مساعدة بخصوص شيفرة التصور البياني، كانت النتيجة ملف JSON معطوبًا لا يفتح أصلًا. جرّبت إرسال مقتطفات قصيرة بدل الملف كاملًا، لكن ذلك انتزع من الذكاء الاصطناعي السياق المهم المرتبط بخطوات المعالجة المسبقة. وفي الوقت نفسه، كنت أوزع انتباهي بين ثلاث نوافذ: Jupyter في المتصفح، وVS Code للبرمجة "الجدية"، ومحرر آخر للتوثيق. هذا المزيج من قيود LLM وصيغة Jupyter وتبديل السياق المستمر جعل العمل المعقد على البيانات شبه مستحيل. وحتى مع مجموعة بيانات أبسط مثل Iris، كانت هذه الفجوة الأساسية تستنزف إنتاجيتي.
هل يبدو لك هذا مألوفًا؟ سير العمل في علم البيانات مرهق أصلًا بسبب كثرة التنقل بين الأدوات. فأنت تنتقل باستمرار بين:
- محررات الشيفرة للبرمجة "الجدية"
- دفاتر Jupyter للاستكشاف
- أدوات التوثيق لمشاركة النتائج
- برامج التصور البياني لإنشاء الرسوم
- ChatGPT وClaude المفتوحين في المتصفح لطرح الأسئلة
كل انتقال يستهلك طاقة ذهنية ثمينة ويضيف احتكاكًا يبطئ الاكتشاف. لكن ماذا لو وُجد أسلوب أفضل؟
تفضّل شرحًا بالفيديو؟ أعددت عرضًا عمليًا خطوة بخطوة لهذا المسار كاملًا. شاهد الشرح الكامل لاستخدام Jupyter Notebooks في Cursor IDE لتحليل البيانات بالذكاء الاصطناعي لترى هذه الأساليب أثناء التطبيق.
الاكتشاف: سير عمل موحّد لعلم البيانات في Cursor IDE
هنا صادفت الحل الذي غيّر طريقتي في العمل: استخدام دفاتر Jupyter مباشرة في Cursor IDE مع الاستفادة من الذكاء الاصطناعي. هذا الأسلوب يجمع بين:
- التنفيذ التفاعلي المعتمد على الخلايا في Jupyter
- قدرات التحرير والتنقل التي تتوقعها من IDE حقيقي
- مساعدة بالذكاء الاصطناعي تفهم الشيفرة ومفاهيم علم البيانات معًا
- ملفات نصية عادية تنسجم بسلاسة مع أنظمة التحكم بالإصدارات
وبحلول نهاية هذا المقال، سأريك كيف بنيت بيئة متكاملة تسمح لي بأن:
- أحلل مجموعات البيانات وأنشئ تصورات بيانية بأقل قدر ممكن من الكتابة اليدوية
- أبني رسومًا ثلاثية الأبعاد تكشف أنماطًا خفية في البيانات
- أوثّق نتائجي إلى جانب الشيفرة بصيغة أنيقة وواضحة
- أصدّر تقارير احترافية بأمر واحد
- أنجز كل ذلك من دون التنقل بين أدوات متفرقة
إذا كنت تريد وضع حد لفوضى تبديل السياق، فلنبدأ.
إعداد بيئة Jupyter في Cursor IDE: الأساس
كل رحلة جيدة تحتاج إلى تجهيز. وحتى تستخدم Jupyter في Cursor IDE، عليك تثبيت الأدوات المناسبة وضبط البيئة بشكل صحيح.
تثبيت إضافة Jupyter
تبدأ الخطوة الأولى مع إضافة Jupyter الرسمية في Cursor IDE:
- افتح Cursor IDE وأنشئ مجلدًا للمشروع
- انتقل إلى قسم Extensions في الشريط الجانبي
- ابحث عن "Jupyter" واختر الإضافة الرسمية
- اضغط "Install"
هذه الإضافة هي الجسر بين دفاتر Jupyter التقليدية وبيئة التطوير. كما تفتح لك ميزة مهمة جدًا: استخدام علامات خاصة داخل ملفات Python العادية لإنشاء خلايا قابلة للتنفيذ. وبهذا لا تعود مضطرًا للتعامل مع ملفات .ipynb ذات البنية المعقدة، بل يمكنك العمل في ملف Python نصي بسيط مع بعض العلامات الواضحة.
إذا أردت معرفة المزيد عن دفاتر Jupyter وقدراتها، فراجع الوثائق الرسمية لـ Jupyter Notebook، فهي تقدم شرحًا شاملًا للميزات وطريقة الاستخدام.
تجهيز بيئة Python
بعد تثبيت الإضافة، حان وقت إعداد بيئة Python نظيفة:
python -m venv .venv
بعد ذلك أنشئ ملف pyproject.toml لإدارة الاعتماديات بصورة حديثة وواضحة:
[build-system]
requires = ["setuptools>=68.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "jupyter-cursor-project"
version = "0.1.0"
description = "تحليل البيانات باستخدام Jupyter داخل Cursor IDE"
requires-python = ">=3.11"
dependencies = [
"jupyter>=1.0.0",
"pandas>=2.1.0",
"numpy>=1.25.0",
"matplotlib>=3.8.0",
"seaborn>=0.13.0",
"scikit-learn>=1.2.0"
]
[tool.setuptools]
py-modules = []
ثم ثبّت هذه الاعتماديات داخل البيئة الافتراضية:
python -m pip install -e .
تعلّمت بالطريقة الصعبة أن تضارب الإصدارات قد يسبب أخطاء غامضة ومربكة. وعندما يقترح عليك الذكاء الاصطناعي شيفرة تستورد مكتبات معيّنة، تحقّق أولًا من أن هذه المكتبات مثبتة فعلًا في بيئتك.
إنشاء أول دفتر: قوة النص العادي
تستخدم دفاتر Jupyter التقليدية صيغة .ipynb، وهي بنية JSON معقدة يصعب تحريرها مباشرة، ويكاد يكون من المستحيل على أدوات الذكاء الاصطناعي تعديلها من دون إفسادها. لذلك سنستخدم نهجًا نصيًا يمنحنا أفضل ما في العالمين.
المشكلة في دفاتر Jupyter الأصلية
هذا مثال سريع على شكل ملف .ipynb عندما تفتحه في محرر نصوص:
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# عنوان الدفتر\n",
"هذه خلية Markdown تحتوي على نص."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": ["مرحبًا بالعالم!"]
}
],
"source": [
"print(\"مرحبًا بالعالم!\")"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
هذه البنية صعبة على نماذج اللغة المستخدمة في ميزات الذكاء الاصطناعي في Cursor للأسباب التالية:
- صيغة JSON مليئة بالرموز والبنى المتداخلة التي لا ترتبط مباشرة بالمحتوى نفسه
- محتوى كل خلية محفوظ داخل مصفوفة من السلاسل النصية مع محارف هروب للأسطر والاقتباسات
- الشيفرة ومخرجاتها منفصلتان في أجزاء مختلفة من البنية
- أي تعديل بسيط يتطلب فهم مخطط JSON كاملًا حتى لا ينكسر الملف
- التغييرات الصغيرة في المحتوى تنتج فروقات كبيرة في JSON، ما يجعل التعديلات الدقيقة أصعب على الذكاء الاصطناعي
وعندما يحاول نموذج لغة كبير تعديل هذه الصيغة، فإنه غالبًا يعجز عن الحفاظ على البنية الصحيحة للملف أثناء إجراء تغييرات مفيدة في المحتوى. والنتيجة تكون دفاتر معطوبة لا تفتح أو لا تعمل كما ينبغي.
سحر علامات الخلايا
أنشئ ملفًا باسم main.py وأضف أول خلية:
# %%
# استيراد المكتبات الأساسية
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# إعدادات العرض لقراءة الجداول والرسوم بوضوح أكبر
pd.set_option('display.max_columns', None)
plt.style.use('ggplot')
print("أصبحت البيئة جاهزة لتحليل البيانات")
هل ترى العلامة # %% في الأعلى؟ هذه هي العلامة التي تخبر إضافة Jupyter بأن هذا الجزء خلية شيفرة. وعندما تضيفها، ستلاحظ ظهور أزرار تشغيل بجانبها. يمكنك تنفيذ هذه الخلية وحدها، وستظهر النتائج مباشرة داخل المحرر.
لنضف الآن خلية Markdown للتوثيق:
# %% [markdown]
"""
# تحليل مجموعة بيانات Iris
يستكشف هذا الدفتر مجموعة بيانات زهرة Iris الشهيرة بهدف فهم:
- العلاقات بين القياسات المختلفة للزهور
- كيف تساعد هذه القياسات في التمييز بين الأنواع
- أي الخصائص تقدم أوضح فصل بين الأنواع
تنتمي كل زهرة في هذه المجموعة إلى أحد ثلاثة أنواع:
1. Setosa
2. Versicolor
3. Virginica
"""
هذه تركيبة قوية جدًا: شيفرة قابلة للتنفيذ وتوثيق غني داخل الملف النصي نفسه. لا صيغ خاصة، ولا قيود تحرير مرتبطة بالمتصفح، بل نص واضح يتعامل جيدًا مع أنظمة التحكم بالإصدارات.
وأثناء بناء الدفتر، سنسير وفق هذا النمط:
- استخدم
# %%لخلايا الشيفرة - استخدم
# %% [markdown]مع علامات الاقتباس الثلاثية لخلايا التوثيق - حافظ على تسلسل منطقي يبدأ بتحميل البيانات ثم الاستكشاف ثم التصور البياني
- وثّق خطواتك ونتائجك أثناء التقدّم
إطلاق مساعد نماذج اللغة الكبيرة: شريكك في علم البيانات
ما يجعل هذا الأسلوب مختلفًا فعلًا هو الدمج مع أداة Composer في Cursor. لا نتحدث هنا عن إكمال تلقائي بسيط، بل عن شريك تعاوني يفهم تحليل البيانات.
وضع الوكيل Agent Mode: رفيق علم بيانات مدعوم بالذكاء الاصطناعي
في Cursor IDE، اضغط على زر Composer ثم اختر Agent Mode. هذا يفعّل مساعدًا أكثر تطورًا يستطيع أن:
- يحافظ على السياق عبر عدة تفاعلات
- يفهم مجموعة البيانات وأهداف التحليل
- يولّد خلايا كاملة بصياغة Jupyter الصحيحة
- ينشئ تصورات بيانية مناسبة لبياناتك الفعلية
لنبدأ بطلب استيراد مجموعة بيانات:
استورد مجموعة بيانات Iris في هذا الدفتر باستخدام تنسيق الخلايا نفسه
سيولّد الذكاء الاصطناعي خلية كاملة قابلة للتنفيذ:
# %%
# استيراد المكتبات المطلوبة
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# تحميل مجموعة بيانات Iris
iris = load_iris()
# تحويلها إلى DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['species'] = iris.target
# عرض الصفوف الأولى
print(df.head())
بمجرد طلب واحد بسيط، تحصل على خلية مكتملة ومنسقة لتحميل البيانات. لا حاجة إلى تذكّر الصياغة الدقيقة أو أسماء الدوال، فالذكاء الاصطناعي يتولى ذلك.
لكن الفائدة الحقيقية تظهر عندما تطلب رسمًا أكثر طموحًا:
أنشئ رسمًا مبعثرًا ثلاثي الأبعاد لمجموعة بيانات Iris مع تمييز الأنواع الثلاثة بألوان مختلفة
عندها ينشئ تصورًا ثلاثي الأبعاد متقدمًا مع حركة دوران:
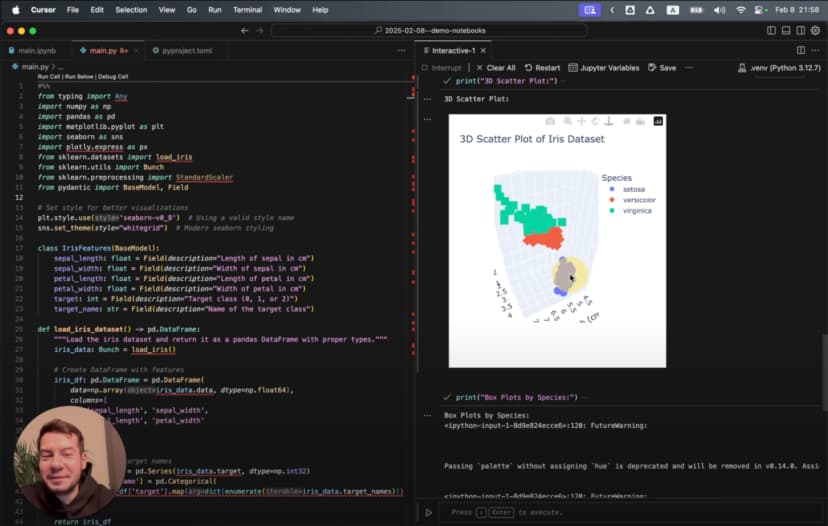
# %%
# إنشاء رسم مبعثر ثلاثي الأبعاد
from mpl_toolkits.mplot3d import Axes3D
# إنشاء الشكل والمحور ثلاثي الأبعاد
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# أسماء الأنواع والألوان المستخدمة
species_names = iris.target_names
colors = ['blue', 'red', 'green']
# رسم كل نوع بلون مختلف
for species_id, species_name in enumerate(species_names):
species_data = df[df['species'] == species_id]
ax.scatter(
species_data['sepal length (cm)'],
species_data['sepal width (cm)'],
species_data['petal length (cm)'],
c=colors[species_id],
label=species_name,
s=60,
alpha=0.8
)
# ضبط العناوين والمحاور
ax.set_xlabel('طول السبلة (سم)')
ax.set_ylabel('عرض السبلة (سم)')
ax.set_zlabel('طول البتلة (سم)')
ax.set_title('رسم مبعثر ثلاثي الأبعاد لمجموعة Iris')
ax.legend()
# إضافة دوران لإظهار البيانات من زوايا متعددة
for angle in range(0, 360, 5):
ax.view_init(30, angle)
plt.draw()
plt.pause(0.001)
plt.show()
هذا ليس مجرد رسم بسيط، بل تصور ثلاثي الأبعاد متحرك يدور ليعرض البيانات من زوايا متعددة، مع عناوين واضحة وألوان مناسبة وتنسيق متقن. وكل ذلك انطلاقًا من طلب واحد.
توجيه نموذج اللغة بقواعد Cursor للحصول على شيفرة أفضل
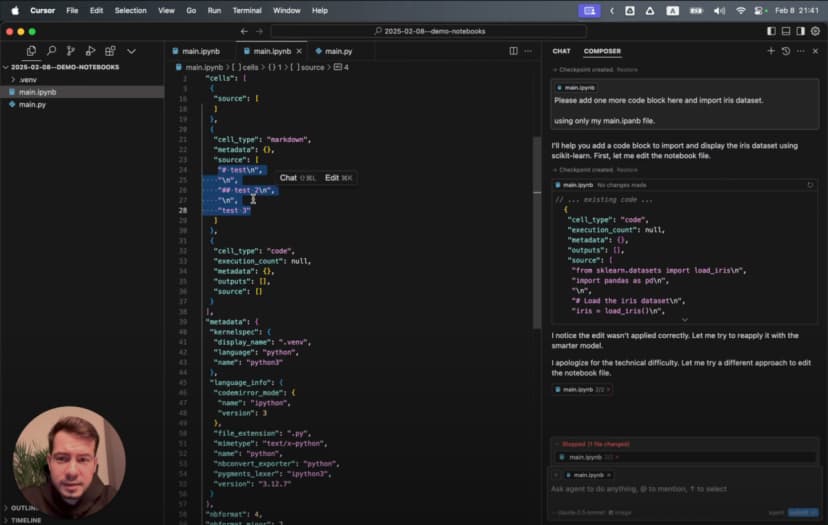
اكتشفت أن بإمكاني جعل الذكاء الاصطناعي أكثر فائدة عبر إنشاء ملف .cursorrules في جذر المشروع. هذا الملف يضم تعليمات مخصصة توجه طريقة توليد الشيفرة.
إذا أردت شرحًا مفصلًا لهذا الجانب، فراجع مقالتي عن تحسين البرمجة بالذكاء الاصطناعي باستخدام Cursor rules.
على سبيل المثال، أضفت القواعد التالية:
<cursorrules_code_style>
- فضّل البرمجة الوظيفية على البرمجة الكائنية
- استخدم دوال نقية بمدخلات ومخرجات واضحة
- استخدم أنواعًا صريحة لكل المتغيرات والدوال
</cursorrules_code_style>
<cursorrules_python_specifics>
- فضّل نماذج Pydantic بدل TypedDict للهياكل المعقدة
- استخدم pyproject.toml بدل requirements.txt
- تجنب المجموعات العامة عند التعامل مع البنى المركبة
</cursorrules_python_specifics>
ومع وجود هذه القواعد، بدأ الذكاء الاصطناعي يولّد شيفرة آمنة من ناحية الأنواع وتنسجم مع الأسلوب الذي أفضّله:
# %%
# تعريف نموذج Pydantic لضبط الأنواع بوضوح
from pydantic import BaseModel
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
species: int
species_name: str
# تحويل صفوف DataFrame إلى نماذج قوية الأنواع
def convert_to_models(df: pd.DataFrame) -> list[IrisFeatures]:
species_map = {0: "Setosa", 1: "Versicolor", 2: "Virginica"}
return [
IrisFeatures(
sepal_length=row["sepal length (cm)"],
sepal_width=row["sepal width (cm)"],
petal_length=row["petal length (cm)"],
petal_width=row["petal width (cm)"],
species=row["species"],
species_name=species_map[row["species"]]
)
for _, row in df.iterrows()
]
# تحويل عينة صغيرة لأغراض العرض
iris_models = convert_to_models(df.head())
for model in iris_models:
print(model)
وهنا بدأ المساعد يلتزم بالقواعد التي وضعتها بدقة، فأنشأ شيفرة واضحة الأنواع، وقريبة من البرمجة الوظيفية، وتستخدم نماذج Pydantic تمامًا كما طلبت.
استكشاف مجموعة بيانات Iris باستخدام Python: رحلة التحليل
بعد أن أصبحت البيئة جاهزة والمساعد حاضرًا، حان وقت بدء رحلتنا داخل مجموعة بيانات Iris الكلاسيكية.
نظرة أولى على البيانات
البيانات محمّلة بالفعل، لكن لنستكشف بنيتها أولًا:
# %%
# عرض معلومات أساسية عن مجموعة البيانات
print("أبعاد مجموعة البيانات:", df.shape)
print("\nتوزيع الفئات:")
print(df['species'].value_counts())
# إنشاء عمود أوضح لأسماء الأنواع
species_names = {0: 'Setosa', 1: 'Versicolor', 2: 'Virginica'}
df['species_name'] = df['species'].map(species_names)
# عرض الإحصاءات الوصفية
print("\nالإحصاءات الوصفية:")
print(df.describe())
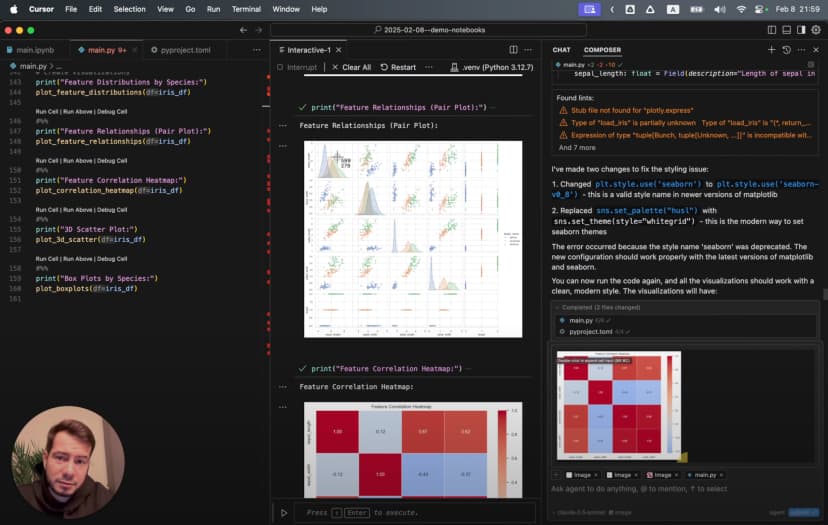
يُظهر هذا أن لدينا 150 عينة، بواقع 50 عينة لكل نوع، مع أربع خصائص تقيس أجزاء مختلفة من الزهرة. والآن لنرسم كل خاصية لنرى كيف تتغيّر عبر الأنواع:
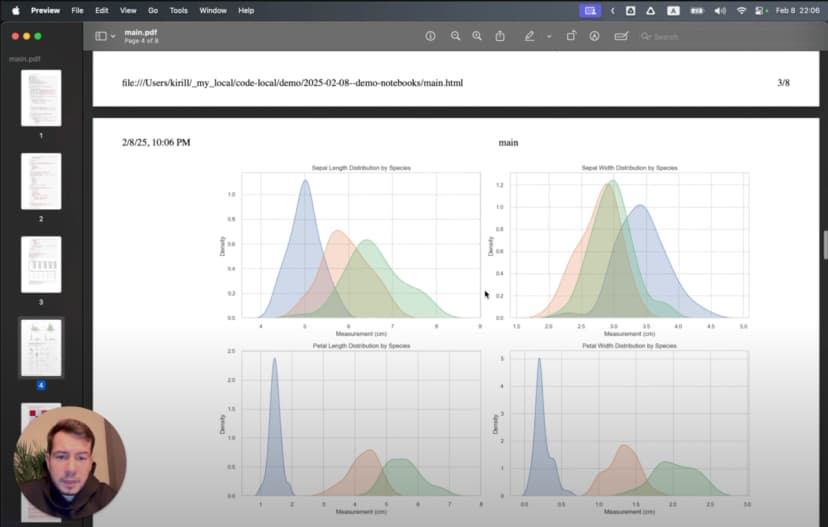
# %%
# إنشاء رسوم صندوقية لكل خاصية بحسب النوع
plt.figure(figsize=(12, 10))
for i, feature in enumerate(iris.feature_names):
plt.subplot(2, 2, i + 1)
sns.boxplot(x='species_name', y=feature, data=df)
plt.title(f'توزيع {feature} بحسب النوع')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
تكشف هذه الرسوم الصندوقية أنماطًا لافتة. يتميز Setosa بسبلات عريضة نسبيًا لكنه يملك بتلات صغيرة، بينما تمتلك Virginica أكبر البتلات عمومًا. لكن أي الخصائص تفصل بين الأنواع بأوضح صورة؟
كشف الأنماط المخفية
للإجابة عن ذلك، علينا أن ننظر في العلاقات بين الخصائص:
# %%
# إنشاء pairplot لإظهار العلاقات بين الخصائص
sns.pairplot(df, hue='species_name', height=2.5)
plt.suptitle('العلاقات الثنائية بين خصائص Iris', y=1.02)
plt.show()
هذا الرسم يوضح بسرعة أن:
- Setosa منفصل تقريبًا بالكامل عن بقية الأنواع في أي رسم يتضمن قياسات البتلات
- هناك بعض التداخل بين Versicolor وVirginica، لكنه لا يمنع تمييزهما
- طول البتلة وعرضها يقدمان أوضح فصل بين الأنواع الثلاثة
لكن أكثر تصور لافت كان الرسم الثلاثي الأبعاد الذي أنشأناه سابقًا. فمع دوران المشهد، تظهر زوايا يصبح فيها الفصل بين المجموعات شديد الوضوح، وهو نوع من الفهم يصعب الوصول إليه عبر رسوم ثنائية الأبعاد ثابتة.
إذا أردت التوسع في تقنيات التحليل والتمثيل البصري للبيانات، فيمكنك الرجوع إلى دليل مستخدم scikit-learn، فهو مرجع ممتاز في التعلم الآلي ومعالجة البيانات.
تجاوز عقبات تكامل Jupyter: تشخيص مشكلات الاعتماديات
لا تخلو أي رحلة من العقبات. ومع الانتقال إلى تصورات أكثر تعقيدًا، اصطدمت بمشكلة: خطأ استيراد متعلق بمكتبة Seaborn.
ImportError: Seaborn not valid package style
وهذا من المشكلات الشائعة في مكتبات علم البيانات: تعارض الإصدارات بين الحزم. ولتشخيص السبب، أضفت خلية تتحقق من الإصدارات المثبتة:
# %%
# التحقق من إصدارات الحزم المثبتة
import pkg_resources
print("الحزم المثبتة:")
for package in ['numpy', 'pandas', 'matplotlib', 'seaborn', 'scikit-learn']:
try:
version = pkg_resources.get_distribution(package).version
print(f"{package}: {version}")
except pkg_resources.DistributionNotFound:
print(f"{package}: غير مثبت")
اكتشفت أن إصدار Seaborn لم يكن متوافقًا مع إصدار NumPy المثبت لدي. وكان الحل استخدام ميزة الطرفية المنبثقة في Cursor:
- اضغط على أيقونة الطرفية في اللوحة السفلية
- اختر "Pop out terminal"
- شغّل أمر التحديث التالي:
python -m pip install --upgrade seaborn
وهنا تحديدًا تظهر قوة Cursor IDE: استطعت حل مشكلة الاعتماديات من دون مغادرة البيئة أو فقدان مكاني في التحليل.
والأفضل من ذلك أنني استطعت عرض رسالة الخطأ على الذكاء الاصطناعي، فاقترح مباشرة الأمر المناسب لإصلاحها. هذا الدمج بين الطرفية المنبثقة والمساعدة الذكية يجعل استكشاف الأخطاء أسرع بكثير مما اعتدت عليه في البيئات التقليدية.
إنشاء تصورات تكشف الأنماط فعلًا: رسوم تفاعلية في Jupyter
بعد أن أصبحت البيئة تعمل بسلاسة، أردت إنشاء تصورات لا تبدو جميلة فقط، بل تكشف فعلًا ما يحدث في البيانات.
من الرسوم البسيطة إلى التصورات ثلاثية الأبعاد
بدأت بمخطط تبعثر بسيط يركز على أبعاد البتلات:
# %%
# إنشاء مخطط تبعثر لأبعاد البتلات
plt.figure(figsize=(10, 6))
for species_id, species_name in enumerate(iris.target_names):
species_data = df[df['species'] == species_id]
plt.scatter(
species_data['petal length (cm)'],
species_data['petal width (cm)'],
label=species_name,
alpha=0.7,
s=70
)
plt.title('أبعاد البتلات بحسب النوع')
plt.xlabel('طول البتلة (سم)')
plt.ylabel('عرض البتلة (سم)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
يوضح هذا الرسم مباشرة كيف تفصل قياسات البتلات بين الأنواع، مع ظهور Setosa كتجمع صغير واضح في الجهة السفلية اليسرى.
ولفهم العلاقات بعمق أكبر، أنشأت خريطة حرارية للارتباطات:
# %%
# حساب مصفوفة الارتباط
correlation_matrix = df.drop(columns=['species_name']).corr()
# إنشاء خريطة حرارية
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation_matrix,
annot=True,
cmap='coolwarm',
linewidths=0.5,
vmin=-1,
vmax=1
)
plt.title('مصفوفة ارتباط خصائص Iris')
plt.show()
أظهرت الخريطة الحرارية ارتباطًا قويًا جدًا، بلغ 0.96، بين طول البتلة وعرضها. وهذا يعني أن هاتين الخاصيتين تتحركان معًا بوضوح في الطبيعة.
لكن التصور الأكثر لفتًا للنظر ظل الرسم الثلاثي الأبعاد المتحرك الذي أنشأناه سابقًا. فمع انتقاله بين زوايا الرؤية المختلفة، ظهرت لحظات تصبح فيها الأنواع الثلاثة منفصلة تمامًا، كاشفة أنماطًا لا يمكن ملاحظتها بالسهولة نفسها في الرسوم الثنائية الثابتة.
هذه هي قوة التمثيل البصري التفاعلي للبيانات: إنه يحوّل الأرقام المجردة إلى فهم بصري مباشر.
مشاركة النتائج: من التحليل إلى العرض
بعد الوصول إلى هذه الاستنتاجات، احتجت إلى مشاركتها مع زملاء لا يملكون Python أو Jupyter مثبتين على أجهزتهم. وهنا تظهر قيمة إمكانات التصدير في إضافة Jupyter.
إنشاء تقارير احترافية
لإنتاج تقرير قابل للمشاركة:
- تأكدت من تنفيذ جميع الخلايا حتى تظهر المخرجات
- أضفت خلايا
Markdownلشرح المنهجية والنتائج - استخدمت خيار "Export as HTML" في إضافة Jupyter
- فتحت ملف HTML في المتصفح ثم استخدمت "Save as PDF" للحصول على مستند نهائي أنيق
النتيجة كانت تقريرًا يضم الشيفرة، والشرح النصي، والتصورات كلها في صيغة يستطيع أي شخص الاطلاع عليها. والاهتمام بتنسيق Markdown أثمر هنا بوضوح: العناوين والقوائم والتأكيدات النصية انتقلت بسلاسة إلى المستند النهائي.
وعند إعداد عرض موجّه إلى أصحاب مصلحة غير تقنيين، كنت أضبط حجم الرسوم وجودتها بما يناسب الطباعة:
plt.figure(figsize=(10, 6), dpi=300)
وهذا يضمن بقاء الرسوم واضحة ومقروءة في ملف PDF.
أما في التصورات ثلاثية الأبعاد، فكنت أختار الزاوية الأكثر إفادة قبل التصدير، لأن ملف PDF سيلتقط لقطة ثابتة فقط من الحركة. هذا التموضع المقصود سمح لي بإبراز النمط الذي أردت التأكيد عليه داخل التقرير.
كيف غيّر هذا الأسلوب سير عملي بالكامل
عندما أنظر إلى هذه الرحلة، يبدو التحول كبيرًا فعلًا. فما كان يتطلب ثلاث أدوات منفصلة وتبديلًا مستمرًا للسياق أصبح يحدث بسلاسة داخل بيئة واحدة. صار سير عملي كالتالي:
- الاستكشاف: أستخدم الذكاء الاصطناعي للمساعدة في تحميل البيانات وإنشاء الرسوم الأولى
- الاكتشاف: أستفيد من تنفيذ الخلايا في Jupyter لتحسين التحليل بصورة تفاعلية
- التوثيق: أضيف خلايا
Markdownلشرح النتائج مباشرة إلى جانب الشيفرة - المشاركة: أصدّر التحليل كاملًا كتقرير احترافي بأمر واحد
الجمع بين تفاعلية Jupyter، وقدرات التحرير القوية في Cursor IDE، ومساعدة الذكاء الاصطناعي أزال الاحتكاك الذي كان يقطع تركيزي باستمرار. وأصبحت حرًا في متابعة فضولي من دون الضريبة الذهنية المصاحبة للتنقل بين الأدوات.
وهناك فائدة إضافية لم أكن أتوقعها: بما أنني أستخدم ملفات نصية عادية بدل دفاتر Jupyter الأصلية، صار التحليل كله خاضعًا للتحكم بالإصدارات عبر Git بصورة سليمة. أستطيع أن أرى التغييرات بدقة بين الإصدارات، وأن أتعاون مع الفريق من دون تعارضات دمج مزعجة، وأن أحافظ على سجل عمل نظيف.
هذا الأسلوب لا يوفر الوقت فقط، بل يغيّر طريقة التفكير في تحليل البيانات نفسها. فعندما يختفي عبء الانقطاع المستمر، يصبح من الأسهل الحفاظ على حالة التدفق وملاحقة الفكرة حتى النهاية. عندها يصبح التحليل أعمق، والتوثيق أكمل، والتصورات أكثر فاعلية.
إذا كنت قد تعبت من موازنة عدة أدوات لإنجاز عمل واحد في علم البيانات، فأنصحك بتجربة هذا النهج المتكامل. أعدّ Jupyter في Cursor IDE، واستفد من المساعد الذكي، واختبر بنفسك كيف يبدو العمل عندما تجتمع الأدوات كلها في مكان واحد. وستقدّر هذا لاحقًا، خصوصًا في تلك الساعات المتأخرة من الليل.
مقارنة: Jupyter التقليدي مقابل Cursor IDE المعزّز بـ LLM
يلخص الجدول التالي الفروقات الأساسية بين أسلوب Jupyter Notebook التقليدي وبين العمل في Cursor IDE باستخدام Jupyter بصيغة نصية:
| الميزة | دفاتر Jupyter التقليدية | Cursor IDE مع Jupyter النصي |
|---|---|---|
| صيغة الملف | JSON معقدة بصيغة .ipynb | ملف Python نصي عادي بصيغة .py |
| التحكم بالإصدارات | صعب بسبب الفروقات الكبيرة وتعارضات الدمج | ممتاز ضمن سير عمل Git المعتاد |
| قدرات الـ IDE | محدودة في التنقل وإعادة الهيكلة | قدرات IDE كاملة مثل البحث والاستبدال والتنقل |
| مساعدة الذكاء الاصطناعي | محدودة | تكامل قوي مع LLM وفهم أفضل للسياق |
| تنفيذ الخلايا | واجهة مبنية على المتصفح | داخل بيئة IDE نفسها |
| تبديل السياق | مطلوب عند التحرير المتقدم | كل شيء في بيئة واحدة |
| الأداء | قد يصبح بطيئًا مع الملفات الكبيرة | أداء محرر أصلي أكثر سلاسة |
| تصحيح الأخطاء | أدوات محدودة | أدوات تصحيح أخطاء كاملة داخل الـ IDE |
| خيارات التصدير | HTML وPDF وصيغ أخرى | الإمكانات نفسها عبر الإضافة |
| التعاون | مربك مع أنظمة التحكم بالإصدارات | أقرب إلى سير عمل التعاون البرمجي المعتاد |
| إدارة الاعتماديات | تُدار غالبًا في ملفات أو إعدادات منفصلة | أكثر تكاملًا داخل بيئة المشروع |
| مشكلات الحالة المخفية | شائعة بسبب التنفيذ خارج الترتيب | أقل بفضل تشجيع التنفيذ الخطي والواضح |
| دعم Markdown | مدمج أصلًا | متاح عبر علامات الخلايا مع القدرات نفسها |
| التحقق من الأنواع | شبه غائب | مدعوم عبر أدوات التحليل الساكن في الـ IDE |
| النظام البيئي للإضافات | إضافات Jupyter | إضافات IDE إضافة إلى إضافات Jupyter |
يوضح هذا الجدول لماذا يقدم نهج Cursor IDE مزايا ملموسة في أعمال تحليل البيانات الجادة، خصوصًا عند الاستفادة من الذكاء الاصطناعي مع الحفاظ على سير عمل سلس.
ولمزيد من التفاصيل عن بنية Jupyter وقدراته، راجع توثيق Project Jupyter، فهو يقدم نظرة عامة على النظام البيئي كاملًا.
فيديو تعليمي: شاهد سير العمل الكامل لـ Jupyter في Cursor IDE
إذا كنت تفضل التعلّم بصريًا، فقد أعددت فيديو شاملًا يشرح كل الأفكار الواردة في هذا المقال:

يعرض الفيديو كل خطوة عمليًا: إعداد دفاتر Jupyter في Cursor IDE، واستخدام التكامل مع الذكاء الاصطناعي، وإنشاء التصورات البيانية، ثم تصدير النتائج، وكل ذلك من دون مغادرة بيئة العمل نفسها.