समस्या: LLM और Jupyter Notebooks साथ में सहजता से काम नहीं करते
रात के 2 बजे आखिरकार मुझे मानना पड़ा कि मैं बुरी तरह अटक गया हूँ। मेरा जीनोमिक सीक्वेंसिंग विश्लेषण इसलिए थम गया था क्योंकि Cursor IDE के भीतर मौजूद LLM सहायक मेरी Jupyter Notebook की जटिल JSON संरचना को ठीक से समझ ही नहीं पा रहा था। जब भी मैं अपने दृश्यांकन वाले कोड में मदद मांगता, बदले में टूटा हुआ JSON मिलता जो खुलता तक नहीं था। मैंने छोटे-छोटे अंश भेजकर भी देखा, लेकिन उससे मेरे पूर्व-प्रसंस्करण चरणों का पूरा संदर्भ गायब हो जाता था। ऊपर से तीन अलग-अलग विंडो हमेशा खुली रहती थीं: ब्राउज़र में Jupyter, "असल" कोड लिखने के लिए VSCode, और दस्तावेज़ लिखने के लिए एक अलग संपादक। Jupyter के फ़ॉर्मैट की सीमाएँ, LLM की दिक्कतें और बार-बार टूल बदलने की मजबूरी, इन सबने मिलकर जटिल डेटा-विश्लेषण को लगभग असंभव बना दिया था। Iris जैसे अपेक्षाकृत सरल मानक डेटा सेट पर भी यही बुनियादी असंगति मेरी उत्पादकता खत्म कर रही थी।
क्या यह अनुभव जाना-पहचाना लगता है? डेटा साइंस के काम में बार-बार संदर्भ बदलना खास तौर पर थका देने वाला होता है। आप लगातार इन चीजों के बीच झूलते रहते हैं:
- गंभीर प्रोग्रामिंग के लिए कोड संपादक
- खोजबीन और प्रयोग के लिए Jupyter Notebooks
- निष्कर्ष साझा करने के लिए दस्तावेज़ीकरण उपकरण
- चार्ट बनाने के लिए दृश्यांकन सॉफ़्टवेयर
- सवाल पूछने के लिए ब्राउज़र में खुले ChatGPT और Claude
हर बार टूल बदलने पर कीमती मानसिक ऊर्जा खर्च होती है और खोज की रफ्तार धीमी पड़ जाती है। लेकिन अगर इससे बेहतर रास्ता हो तो?
वीडियो ट्यूटोरियल देखना पसंद है? मैंने इस पूरे कार्यप्रवाह का चरण-दर-चरण वीडियो बनाया है। AI-संचालित डेटा विश्लेषण के साथ Cursor IDE में Jupyter Notebooks का ट्यूटोरियल देखें।
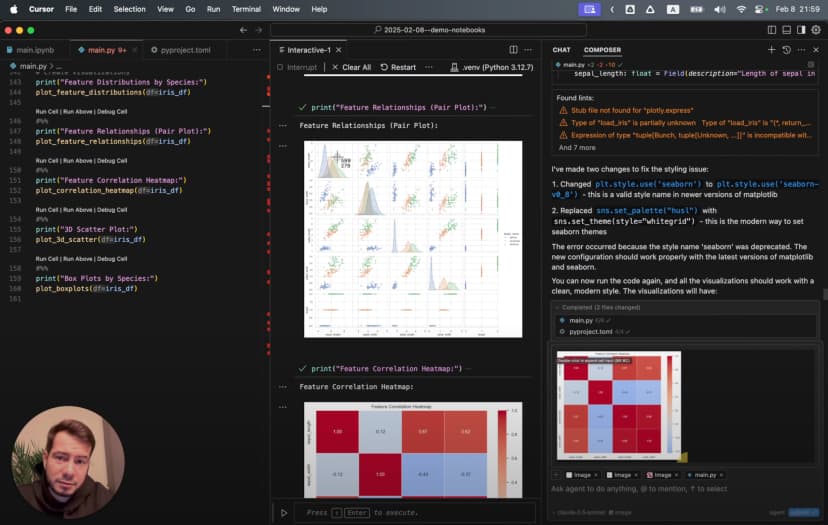
खोज: Cursor IDE में एकीकृत डेटा साइंस कार्यप्रवाह
तभी मुझे एक ऐसा तरीका मिला जिसने मेरा काम करने का पूरा ढंग बदल दिया: Cursor IDE के भीतर सीधे Jupyter Notebooks चलाना, और उस पर कृत्रिम बुद्धिमत्ता की क्षमता जोड़ देना। इस तरीके में एक साथ ये फायदे मिलते हैं:
- Jupyter का इंटरैक्टिव, सेल-आधारित निष्पादन
- एक सक्षम IDE की मजबूत संपादन और नेविगेशन सुविधाएँ
- ऐसी कृत्रिम बुद्धिमत्ता सहायता जो कोड और डेटा साइंस, दोनों का संदर्भ समझती है
- सादा पाठ वाला फ़ाइल प्रारूप, जो संस्करण नियंत्रण के साथ बेहतरीन ढंग से काम करता है
इस लेख के अंत तक मैं दिखाऊँगा कि मैंने ऐसा एकीकृत वातावरण कैसे बनाया, जिसमें मैं:
- बहुत कम हाथ से कोड लिखकर डेटा सेट का विश्लेषण और दृश्यांकन कर सकता हूँ
- ऐसे त्रि-आयामी दृश्यांकन बना सकता हूँ जो डेटा में छिपे पैटर्न उजागर करें
- अपने निष्कर्षों को कोड के साथ ही साफ़-सुथरे ढंग से दर्ज कर सकता हूँ
- एक ही कमांड से पेशेवर स्तर की रिपोर्टें निर्यात कर सकता हूँ
- और यह सब अलग-अलग टूल्स के बीच भटके बिना कर सकता हूँ
अगर आप भी लगातार टूल बदलने की इस थकान से बाहर निकलना चाहते हैं, तो चलिए शुरू करते हैं।
Cursor IDE में Jupyter परिवेश तैयार करना: बुनियाद
हर अच्छे कार्यपरिवेश की शुरुआत तैयारी से होती है। Cursor IDE में Jupyter को ठीक से चलाने के लिए हमें सही औज़ार स्थापित करने और परिवेश को व्यवस्थित ढंग से विन्यस्त करने की ज़रूरत है।
Jupyter extension इंस्टॉल करना
सारी शुरुआत Cursor IDE के लिए Jupyter extension से होती है:
- Cursor IDE खोलें और एक प्रोजेक्ट फ़ोल्डर बनाएँ
- साइडबार में
Extensionsपर जाएँ Jupyterखोजें और लाखों डाउनलोड वाला आधिकारिक extension चुनेंInstallपर क्लिक करें
यह extension पारंपरिक नोटबुक्स और आपके IDE के बीच पुल का काम करती है। इसकी मदद से आप सामान्य Python फ़ाइलों में खास संकेत लिखकर चलाए जा सकने वाले सेल बना सकते हैं। अब जटिल JSON संरचना वाली .ipynb फ़ाइलों पर निर्भर रहना ज़रूरी नहीं रहता; कुछ विशेष संकेतों के साथ साधारण Python पाठ-फ़ाइलों में ही काम हो जाता है।
Jupyter Notebooks और उनकी क्षमताओं के बारे में अधिक जानकारी के लिए आधिकारिक Jupyter Notebook दस्तावेज़ देखें।
Python परिवेश तैयार करना
Extension स्थापित होने के बाद अब एक साफ़-सुथरा Python परिवेश बनाते हैं:
python -m venv .venv
अब निर्भरताओं को व्यवस्थित ढंग से संभालने के लिए pyproject.toml फ़ाइल बनाएँ:
[build-system]
requires = ["setuptools>=42.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "jupyter-cursor-project"
version = "0.1.0"
description = "Data analysis with Jupyter in Cursor IDE"
[tool.poetry.dependencies]
python = "^3.9"
jupyter = "^1.0.0"
pandas = "^2.1.0"
numpy = "^1.25.0"
matplotlib = "^3.8.0"
seaborn = "^0.13.0"
scikit-learn = "^1.2.0"
फिर इसी virtual environment में निर्भरताएँ स्थापित करें:
pip install -e .
मैंने अनुभव से सीखा है कि संस्करण टकराव बहुत रहस्यमय त्रुटियाँ पैदा कर सकते हैं। जब कृत्रिम बुद्धिमत्ता किसी library का import सुझाए, तो पहले यह सुनिश्चित कर लें कि वह आपके परिवेश में सचमुच स्थापित है।
अपनी पहली नोटबुक बनाना: सादे पाठ की ताकत
पारंपरिक Jupyter Notebooks .ipynb प्रारूप का उपयोग करती हैं, जो असल में एक जटिल JSON संरचना होती है। उसे सीधे संपादित करना मुश्किल है, और कृत्रिम बुद्धिमत्ता औज़ारों के लिए बिना फ़ॉर्मैट बिगाड़े उसमें बदलाव करना उससे भी कठिन। इसलिए हम एक ऐसे सादे-पाठ वाले तरीके का उपयोग करेंगे जो दोनों दुनिया के फायदे देता है।
मूल Jupyter Notebooks की समस्या
अगर आप एक पारंपरिक .ipynb फ़ाइल को किसी पाठ-संपादक में खोलें, तो वह कुछ इस तरह दिखती है:
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": ["# My Notebook Title\n", "This is a markdown cell with text."]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": ["Hello, world!"]
}
],
"source": ["print(\"Hello, world!\")"]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
यह संरचना खास तौर पर Cursor जैसे कृत्रिम बुद्धिमत्ता औज़ारों में इस्तेमाल होने वाले LLMs के लिए चुनौतीपूर्ण है, क्योंकि:
- JSON प्रारूप में बहुत सारे प्रतीक और परतदार संरचनाएँ होती हैं, जिनका असली सामग्री से सीधा संबंध नहीं होता
- हर सेल की सामग्री strings की array में रखी जाती है, जिसमें नई पंक्तियों और quotes के लिए escape characters होते हैं
- कोड और उसके परिणाम संरचना के अलग-अलग हिस्सों में बँटे होते हैं
- छोटा-सा संपादन भी पूरी JSON schema समझे बिना सुरक्षित ढंग से नहीं किया जा सकता
- सामग्री में छोटे बदलाव भी JSON में बड़े
diffपैदा करते हैं, इसलिए कृत्रिम बुद्धिमत्ता के लिए सटीक संपादन करना कठिन हो जाता है
जब कोई LLM इस प्रारूप को बदलने की कोशिश करता है, तो वह अक्सर अर्थपूर्ण बदलाव करते हुए सही JSON संरचना बनाए नहीं रख पाता। नतीजा यह होता है कि नोटबुक टूट जाती है और फिर न खुलती है, न ठीक से चलती है।
सेल संकेतों का कमाल
main.py नाम की फ़ाइल बनाएँ और उसमें अपना पहला सेल जोड़ें:
# %%
# आवश्यक लाइब्रेरी आयात करें
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# बेहतर दृश्यांकन के लिए प्रदर्शन सेटिंग्स
pd.set_option('display.max_columns', None)
plt.style.use('ggplot')
print("डेटा विश्लेषण के लिए परिवेश तैयार है!")
ऊपर दिख रहा # %% वही जादुई संकेत है, जो Jupyter extension को बताता है कि "यह एक कोड सेल है"। जैसे ही आप यह संकेत जोड़ते हैं, उसके पास चलाने के बटन दिखाई देने लगते हैं। आप सिर्फ इसी सेल को चला सकते हैं, और उसके परिणाम सीधे अपने संपादक के भीतर देख सकते हैं।
अब दस्तावेज़ीकरण के लिए एक मार्कडाउन सेल जोड़ते हैं:
# %% [markdown]
"""
# Iris डेटा सेट का विश्लेषण
यह नोटबुक प्रसिद्ध Iris flower dataset की पड़ताल करती है, ताकि हम समझ सकें:
- फूल के अलग-अलग मापों के बीच क्या संबंध हैं
- ये माप अलग-अलग प्रजातियों को कैसे अलग पहचानते हैं
- कौन-सी विशेषताएँ प्रजातियों के बीच सबसे साफ़ अंतर दिखाती हैं
डेटा सेट का हर फूल इन तीन प्रजातियों में से किसी एक का है:
1. Setosa
2. Versicolor
3. Virginica
"""
यही इस तरीके की असली ताकत है: चलाया जा सकने वाला कोड और समृद्ध दस्तावेज़ीकरण, दोनों एक ही सादे-पाठ वाली फ़ाइल में। कोई विशेष फ़ाइल प्रारूप नहीं, ब्राउज़र-आधारित संपादन की कोई बंदिश नहीं, सिर्फ साफ़ पाठ जो संस्करण नियंत्रण के साथ बेहतरीन ढंग से चलता है।
जैसे-जैसे हम अपनी नोटबुक बनाएँगे, हम यह ढाँचा अपनाएँगे:
- कोड सेल के लिए
# %%का उपयोग - दस्तावेज़ीकरण के लिए triple quotes के साथ
# %% [markdown] - डेटा लोड करने से खोजबीन और फिर दृश्यांकन तक स्पष्ट तार्किक प्रवाह
- पूरे रास्ते प्रक्रिया और निष्कर्षों का साफ़ लेखा-जोखा
LLM सहायक की पूरी क्षमता खोलना: आपका डेटा साइंस सहयोगी
इस कार्यप्रवाह को वास्तव में अलग बनाता है Cursor के AI Composer के साथ इसका एकीकरण। यह सिर्फ स्वतः-पूरण नहीं है, बल्कि एक सहयोगी साथी की तरह काम करता है जो डेटा साइंस का संदर्भ समझता है।
Agent Mode: कृत्रिम बुद्धिमत्ता-सहायित डेटा साइंस साथी
Cursor IDE में Composer बटन पर क्लिक करें और Agent Mode चुनें। इससे एक अधिक सक्षम कृत्रिम बुद्धिमत्ता सहायक सक्रिय होता है, जो:
- कई दौर की बातचीत के दौरान संदर्भ बनाए रखता है
- आपके डेटा सेट और विश्लेषण के लक्ष्यों को समझता है
- सही Jupyter सिंटैक्स के साथ पूरे कोड सेल बना देता है
- आपके डेटा के अनुरूप दृश्यांकन तैयार करता है
आइए सबसे पहले उससे डेटा सेट आयात करने को कहें:
इस नोटबुक प्रारूप में Iris डेटा सेट आयात करें
कृत्रिम बुद्धिमत्ता एक पूरा चलाया जा सकने वाला सेल तैयार कर देती है:
# %%
# आवश्यक लाइब्रेरी आयात करें
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# Iris डेटा सेट लोड करें
iris = load_iris()
# इसे pandas DataFrame में बदलें
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['species'] = iris.target
# शुरुआती कुछ पंक्तियाँ दिखाएँ
print(df.head())
सिर्फ एक सरल अनुरोध, और हमारे पास ऐसा कोड सेल है जो डेटा सेट को सही ढंग से लोड कर देता है। न आपको सटीक सिंटैक्स याद रखने की ज़रूरत है, न फ़ंक्शन के नाम खोजने की। यह हिस्सा कृत्रिम बुद्धिमत्ता संभाल लेती है।
लेकिन असली कमाल तब दिखता है जब हम उससे दृश्यांकन बनाने को कहते हैं:
Iris डेटा सेट के लिए ऐसा 3D scatter plot बनाइए जिसमें तीनों प्रजातियाँ अलग-अलग रंगों में दिखें
कृत्रिम बुद्धिमत्ता घूमने वाले दृश्य के साथ एक उन्नत 3D दृश्यांकन तैयार करती है:
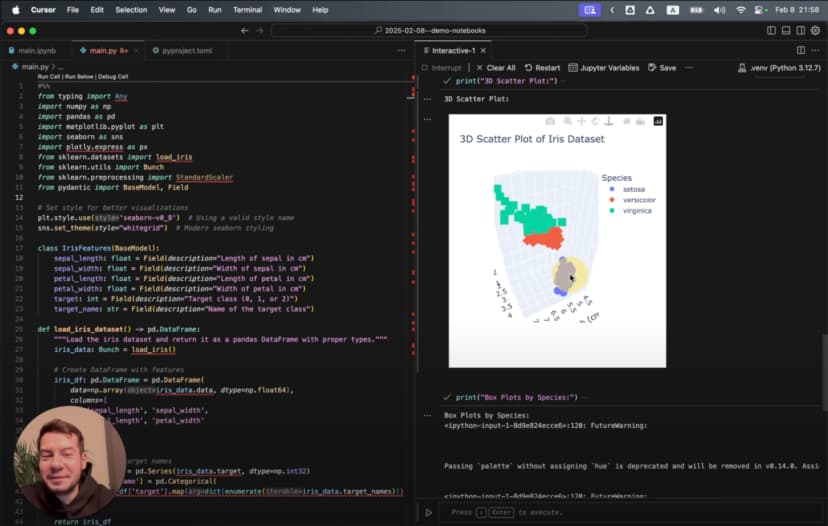
# %%
# 3D scatter plot बनाएँ
from mpl_toolkits.mplot3d import Axes3D
# figure और 3D axis बनाएँ
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# तीनों प्रजातियों के नाम लें
species_names = iris.target_names
colors = ['blue', 'red', 'green']
# हर प्रजाति को अलग रंग में plot करें
for species_id, species_name in enumerate(species_names):
# इस प्रजाति का डेटा छाँटें
species_data = df[df['species'] == species_id]
# इस प्रजाति को plot करें
ax.scatter(
species_data['sepal length (cm)'],
species_data['sepal width (cm)'],
species_data['petal length (cm)'],
c=colors[species_id],
label=species_name,
s=60,
alpha=0.8
)
# axis labels और title सेट करें
ax.set_xlabel('Sepal Length (cm)')
ax.set_ylabel('Sepal Width (cm)')
ax.set_zlabel('Petal Length (cm)')
ax.set_title('Iris डेटा सेट का 3D scatter plot')
ax.legend()
# बेहतर दृश्यांकन के लिए rotation जोड़ें
for angle in range(0, 360, 5):
ax.view_init(30, angle)
plt.draw()
plt.pause(0.001)
plt.show()
यह सिर्फ एक साधारण चार्ट नहीं है। यह गतिशील 3D दृश्यांकन है, जो डेटा को अलग-अलग कोणों से दिखाता है और लेबल, रंग तथा विन्यास भी ठीक ढंग से संभालता है। और यह सब एक ही अनुरोध से।
बेहतर कोड लिखवाने के लिए Cursor Rules से LLM को दिशा देना
मुझे यह भी समझ आया कि अगर प्रोजेक्ट की मुख्य निर्देशिका में .cursorrules फ़ाइल रख दी जाए, तो कृत्रिम बुद्धिमत्ता को कहीं अधिक सटीक दिशा दी जा सकती है। इस फ़ाइल में आप अपने प्रोजेक्ट के लिए वे खास निर्देश लिखते हैं, जिनके मुताबिक वह कोड तैयार करती है।
Cursor Rules को प्रभावी ढंग से सेट करने और इस्तेमाल करने के लिए आप मेरा विस्तृत लेख Cursor Rules की मदद से AI-आधारित कोड लेखन को बेहतर बनाने पढ़ सकते हैं।
उदाहरण के लिए, मैंने इसमें ये निर्देश जोड़े:
<cursorrules_code_style>
- OOP की जगह फलन-आधारित शैली को प्राथमिकता दें
- साफ़ input/output वाले pure functions इस्तेमाल करें
- सभी variables और functions के लिए सख्त typing रखें
</cursorrules_code_style>
<cursorrules_python_specifics>
- data models के लिए TypedDict की जगह Pydantic को प्राथमिकता दें
- requirements.txt की जगह pyproject.toml का उपयोग करें
- जटिल structures में generic collections से बचें
</cursorrules_python_specifics>
इन निर्देशों के बाद कृत्रिम बुद्धिमत्ता ने मेरी पसंद के अनुरूप, प्रकार-सुरक्षित कोड बनाना शुरू कर दिया:
# %%
# बेहतर type safety के लिए Pydantic model परिभाषित करें
from pydantic import BaseModel
from typing import List, Optional
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
species: int
species_name: Optional[str] = None
# DataFrame की पंक्तियों को Pydantic models में बदलने वाला function
def convert_to_models(df: pd.DataFrame) -> List[IrisFeatures]:
species_map = {0: "setosa", 1: "versicolor", 2: "virginica"}
return [
IrisFeatures(
sepal_length=row["sepal length (cm)"],
sepal_width=row["sepal width (cm)"],
petal_length=row["petal length (cm)"],
petal_width=row["petal width (cm)"],
species=row["species"],
species_name=species_map[row["species"]]
)
for _, row in df.iterrows()
]
# प्रदर्शन के लिए एक नमूना बदलें
iris_models = convert_to_models(df.head())
for model in iris_models:
print(model)
कृत्रिम बुद्धिमत्ता ने मेरे निर्देशों का ठीक वैसा ही पालन किया जैसा मैं चाहता था: स्पष्ट प्रकार-निर्देशन, फलन-आधारित शैली और Pydantic models के साथ।
Python के साथ Iris डेटा सेट की पड़ताल: हमारा विश्लेषण अभियान
अब परिवेश भी तैयार है और कृत्रिम बुद्धिमत्ता सहायक भी, तो चलिए Iris डेटा सेट की पड़ताल शुरू करते हैं।
डेटा पर पहली नज़र
डेटा सेट हमने पहले ही लोड कर लिया है, लेकिन अब इसकी संरचना समझते हैं:
# %%
# डेटा सेट की बुनियादी जानकारी लें
print("डेटा सेट का आकार:", df.shape)
print("\nप्रजातियों का वितरण:")
print(df['species'].value_counts())
# प्रजाति नाम का अधिक पढ़ने योग्य column बनाएँ
species_names = {0: 'setosa', 1: 'versicolor', 2: 'virginica'}
df['species_name'] = df['species'].map(species_names)
# वर्णनात्मक आँकड़े दिखाएँ
print("\nवर्णनात्मक आँकड़े:")
print(df.describe())
इससे पता चलता है कि हमारे पास 150 नमूने हैं, हर प्रजाति के 50, और फूलों के अलग-अलग हिस्सों को मापने वाली 4 विशेषताएँ हैं। अब देखते हैं कि ये विशेषताएँ प्रजातियों के अनुसार कैसे बदलती हैं:
# %%
# हर feature के लिए प्रजाति-आधारित boxplots बनाएँ
plt.figure(figsize=(12, 10))
for i, feature in enumerate(iris.feature_names):
plt.subplot(2, 2, i+1)
sns.boxplot(x='species_name', y=feature, data=df)
plt.title(f'प्रजाति के अनुसार {feature} का वितरण')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
इन बॉक्स-प्लॉटों से कई रोचक बातें सामने आती हैं। Setosa के बाह्यदल अपेक्षाकृत चौड़े हैं, लेकिन पंखुड़ियाँ छोटी हैं। Virginica की पंखुड़ियाँ सबसे बड़ी दिखाई देती हैं। लेकिन कौन-सी विशेषताएँ प्रजातियों के बीच सबसे साफ़ अंतर दिखाती हैं?
छिपे हुए पैटर्न सामने लाना
इसका जवाब पाने के लिए हमें विशेषताओं के बीच संबंध देखने होंगे:
# %%
# features के बीच संबंध दिखाने के लिए pairplot बनाएँ
sns.pairplot(df, hue='species_name', height=2.5)
plt.suptitle('Iris डेटा सेट में pairwise संबंध', y=1.02)
plt.show()
यह pairplot कई बातें एकदम साफ़ कर देता है। इससे तुरंत दिखता है कि:
- पंखुड़ियों के माप वाले किसी भी प्लॉट में Setosa बाकी प्रजातियों से पूरी तरह अलग दिखाई देती है
- Versicolor और Virginica में कुछ ओवरलैप है, लेकिन फिर भी उन्हें अलग पहचाना जा सकता है
- पंखुड़ी की लंबाई और चौड़ाई, तीनों प्रजातियों के बीच सबसे स्पष्ट अलगाव देती हैं
सबसे प्रभावशाली दृश्यांकन वही 3D scatter plot है, जिसमें तीनों प्रजातियाँ त्रि-आयामी स्थान में अलग-अलग समूह बनाती दिखती हैं। उसे घुमाकर देखने पर कुछ ऐसे कोण सामने आते हैं, जहाँ यह अलगाव बिल्कुल साफ़ दिखाई देता है। स्थिर 2D चित्र के साथ ऐसी अंतर्दृष्टि पाना लगभग असंभव होता।
अधिक उन्नत दृश्यांकन और डेटा विश्लेषण तकनीकों के लिए scikit-learn User Guide एक उत्कृष्ट संदर्भ है, जिसमें मशीन लर्निंग एल्गोरिद्म और डेटा पूर्व-प्रसंस्करण विधियों दोनों पर विस्तृत जानकारी मिलती है।
Jupyter एकीकरण की रुकावटें दूर करना: निर्भरताओं की समस्या-सुलझाई
हर कामकाजी व्यवस्था में कुछ न कुछ अड़चनें आती हैं। जब मैंने थोड़ा अधिक जटिल दृश्यांकन बनाना शुरू किया, तो Seaborn import से जुड़ी यह समस्या सामने आई:
ImportError: Seaborn not valid package style
डेटा साइंस की लाइब्रेरी के साथ संस्करण असंगति आम बात है। इसकी जाँच करने के लिए मैंने स्थापित संस्करण दिखाने वाला एक सेल जोड़ा:
# %%
# स्थापित packages के versions जाँचें
import pkg_resources
print("स्थापित packages:")
for package in ['numpy', 'pandas', 'matplotlib', 'seaborn', 'scikit-learn']:
try:
version = pkg_resources.get_distribution(package).version
print(f"{package}: {version}")
except pkg_resources.DistributionNotFound:
print(f"{package}: स्थापित नहीं")
यहीं पता चला कि Seaborn का स्थापित संस्करण, NumPy के संस्करण के साथ मेल नहीं खा रहा था। इसे ठीक करने के लिए मैंने Cursor की उस टर्मिनल सुविधा का उपयोग किया जो अलग विंडो में खुलती है:
- नीचे के भाग में दिख रहे
terminalicon पर क्लिक करें Pop out terminalचुनें- यह कमांड चलाएँ:
pip install seaborn --upgrade
यहीं Cursor IDE की असली उपयोगिता सामने आती है। निर्भरता से जुड़ी समस्या सुलझाने के लिए मुझे न किसी दूसरे औज़ार में जाना पड़ा, न अपने विश्लेषण का सिलसिला तोड़ना पड़ा।
इससे भी बेहतर बात यह थी कि मैंने त्रुटि संदेश कृत्रिम बुद्धिमत्ता को दिखाया, और उसने ठीक वही कमांड सुझाई जिसकी ज़रूरत थी। अलग विंडो में खुली टर्मिनल और उसकी सहायता का यह मेल समस्या-सुलझाने को पारंपरिक वातावरण की तुलना में कहीं तेज़ बना देता है।
दृश्यांकन से अंतर्दृष्टि निकालना: Jupyter में इंटरैक्टिव चार्ट
अब जब परिवेश सुचारु रूप से चल रहा था, तो मेरा लक्ष्य ऐसे दृश्यांकन बनाना था जो हमारे डेटा के पैटर्न सचमुच सामने ला सकें।
साधारण चार्ट से 3D दृश्यांकन तक
मैंने शुरुआत पंखुड़ियों के आयामों पर आधारित एक सरल scatter plot से की:
# %%
# पंखुड़ियों के आयामों का scatter plot बनाएँ
plt.figure(figsize=(10, 6))
for species_id, species_name in enumerate(iris.target_names):
species_data = df[df['species'] == species_id]
plt.scatter(
species_data['petal length (cm)'],
species_data['petal width (cm)'],
label=species_name,
alpha=0.7,
s=70
)
plt.title('प्रजाति के अनुसार पंखुड़ी के आयाम')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
यह plot तुरंत दिखा देता है कि पंखुड़ियों के माप प्रजातियों को अलग करने में कितने उपयोगी हैं। Setosa नीचे बाईं ओर एक घना समूह बनाती दिखाई देती है।
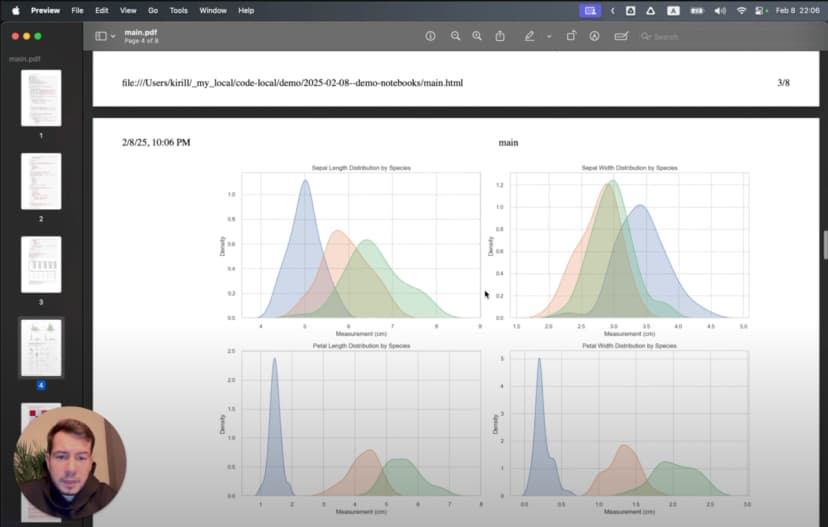
रिश्तों को और गहराई से समझने के लिए मैंने correlation heatmap बनाई:
# %%
# correlation matrix निकालें
correlation_matrix = df.drop(columns=['species_name']).corr()
# heatmap बनाएँ
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation_matrix,
annot=True,
cmap='coolwarm',
linewidths=0.5,
vmin=-1,
vmax=1
)
plt.title('Iris features की correlation matrix')
plt.show()
इस heatmap से साफ़ दिखा कि पंखुड़ी की लंबाई और चौड़ाई के बीच 0.96 का बहुत मजबूत सहसंबंध है। यानी प्रकृति में ये दोनों विशेषताएँ साथ-साथ बदलती हैं।
लेकिन सबसे उल्लेखनीय दृश्यांकन वही गतिशील 3D scatter plot रहा, जिसे हमने पहले बनाया था। अलग-अलग कोणों से देखते हुए वह ऐसे क्षण दिखाता है, जहाँ तीनों प्रजातियाँ पूरी तरह अलग नज़र आती हैं। यही इंटरैक्टिव डेटा दृश्यांकन की असली शक्ति है: अमूर्त संख्याओं को सहज और लगभग अनुभवजन्य समझ में बदल देना।
अपनी खोजें साझा करना: विश्लेषण से प्रस्तुति तक
इन निष्कर्षों को सामने लाने के बाद अगली ज़रूरत थी उन्हें उन साथियों के साथ साझा करना, जिनके सिस्टम पर Python या Jupyter स्थापित नहीं था। यहीं Jupyter extension की निर्यात सुविधाएँ बेहद मूल्यवान साबित होती हैं।
पेशेवर रिपोर्टें बनाना
साझा की जा सकने वाली रिपोर्ट तैयार करने के लिए मैंने यह किया:
- यह सुनिश्चित किया कि सभी सेल चल चुके हों और उनके परिणाम दिखाई दे रहे हों
- कार्यविधि और निष्कर्ष समझाने के लिए मार्कडाउन सेल जोड़े
- Jupyter extension के
Export as HTMLविकल्प का उपयोग किया - HTML फ़ाइल को ब्राउज़र में खोला और
Save as PDFसे एक सुघड़ दस्तावेज़ बनाया
अंतिम रिपोर्ट में मेरा कोड, पाठ्य व्याख्याएँ और दृश्यांकन, सब कुछ ऐसे स्वरूप में आ गया जिसे कोई भी देख सकता था। Markdown स्वरूपण पर दिया गया ध्यान यहाँ काम आया: खंड शीर्षक, बिंदुवार सूची और जोर दिए गए अंश, सब अंतिम दस्तावेज़ में ठीक से बने रहे।
गैर-तकनीकी हितधारकों के लिए प्रस्तुति तैयार करते समय मैं दृश्यांकनों का आकार उपयुक्त रखता हूँ, जैसे figsize=(10, 6), और छपाई-योग्य गुणवत्ता के लिए उच्च DPI का उपयोग करता हूँ:
plt.figure(figsize=(10, 6), dpi=300)
इससे PDF निर्यात में चार्ट साफ़ और पढ़ने योग्य बने रहते हैं।
3D दृश्यांकन के मामले में, निर्यात करने से पहले मैं उसे उस कोण पर सेट करता हूँ जहाँ पैटर्न सबसे स्पष्ट दिखाई दे। क्योंकि घूमता हुआ दृश्य अंततः एक स्थिर चित्र के रूप में ही दर्ज होता है, इसलिए सही कोण चुनना रिपोर्ट में सही बिंदु उभारने के लिए बहुत महत्वपूर्ण है।
कार्यप्रवाह में आया बदलाव: Cursor IDE में LLM-संचालित डेटा साइंस
पीछे मुड़कर देखूँ तो यह बदलाव काफ़ी बड़ा है। जो काम पहले तीन अलग औज़ारों और लगातार संदर्भ बदलने की थकान के साथ होता था, वह अब एक ही परिवेश में सहज रूप से हो जाता है। मेरा कार्यप्रवाह अब कुछ ऐसा है:
- पड़ताल: कृत्रिम बुद्धिमत्ता की मदद से डेटा लोड करना और शुरुआती दृश्यांकन बनाना
- खोज: Jupyter की सेल-आधारित निष्पादन शैली के सहारे विश्लेषण को इंटरैक्टिव ढंग से परिष्कृत करना
- दस्तावेज़ीकरण: निष्कर्षों को सीधे कोड के साथ मार्कडाउन सेल में लिखना
- साझा करना: पूरे विश्लेषण को एक ही कमांड से पेशेवर रिपोर्ट के रूप में निर्यात करना
Jupyter की इंटरैक्टिव प्रकृति, Cursor IDE की शक्तिशाली संपादन सुविधाएँ और कृत्रिम बुद्धिमत्ता सहायता, इन तीनों के मेल ने वह रुकावट खत्म कर दी है जो पहले मेरी एकाग्रता तोड़ देती थी। अब मैं लगातार टूल बदलने की कीमत चुकाए बिना अपनी जिज्ञासा के पीछे जा सकता हूँ।
और एक अप्रत्याशित लाभ भी मिला: क्योंकि मैं मूल Jupyter notebooks की बजाय सादे-पाठ वाली फ़ाइलों का उपयोग कर रहा हूँ, मेरा पूरा विश्लेषण अब Git में ठीक से संस्करण नियंत्रण के भीतर है। मैं साफ़-साफ़ देख सकता हूँ कि अलग-अलग संस्करणों के बीच क्या बदला, साथ काम करने वालों के साथ अनावश्यक merge conflict के बिना सहयोग कर सकता हूँ, और अपने काम का साफ़ इतिहास बनाए रख सकता हूँ।
यह तरीका सिर्फ समय नहीं बचाता, बल्कि डेटा विश्लेषण के बारे में मेरी सोच भी बदल देता है। जब बार-बार संदर्भ नहीं टूटता, तो गहरी एकाग्रता की अवस्था बनाए रखना आसान हो जाता है। इससे विश्लेषण अधिक गहरा होता है, दस्तावेज़ीकरण अधिक पूरा होता है, और दृश्यांकन अधिक प्रभावशाली बनते हैं।
अगर आप भी डेटा साइंस के काम के लिए कई औज़ार संभालते-संभालते थक चुके हैं, तो इस एकीकृत तरीके को ज़रूर आज़माइए। Cursor IDE में Jupyter की व्यवस्था कीजिए, कृत्रिम बुद्धिमत्ता सहायक का लाभ उठाइए, और इस एकजुट कार्यप्रवाह की शक्ति महसूस कीजिए। आपका भविष्य वाला रूप, ख़ासकर रात के 2 बजे वाला, आपको इसके लिए धन्यवाद देगा।
तुलना: पारंपरिक Jupyter बनाम LLM-सक्षम Cursor IDE
नीचे एक त्वरित तुलना दी गई है, जो पारंपरिक Jupyter Notebook तरीके और Cursor IDE के सादे-पाठ वाले Jupyter कार्यप्रवाह के बीच मुख्य अंतर स्पष्ट करती है:
| विशेषता | पारंपरिक Jupyter Notebooks | सादे-पाठ वाले Jupyter के साथ Cursor IDE |
|---|---|---|
| फ़ाइल प्रारूप | जटिल JSON (.ipynb) | सादा पाठ Python (.py) |
| संस्करण नियंत्रण | कठिन (diff बड़े, merge conflict आम) | उत्कृष्ट (सामान्य Git कार्यप्रवाह) |
| IDE सुविधाएँ | सीमित कोड नेविगेशन और पुनर्रचना | पूरी IDE क्षमताएँ (खोज, बदलना, नेविगेशन) |
| कृत्रिम बुद्धिमत्ता सहायता | सीमित | संदर्भ समझने वाला शक्तिशाली LLM एकीकरण |
| सेल निष्पादन | ब्राउज़र-आधारित इंटरफ़ेस | IDE के भीतर मूल रूप से |
| बार-बार टूल बदलना | उन्नत संपादन के लिए ज़रूरी | लगभग सब कुछ एक ही परिवेश में |
| प्रदर्शन | बड़ी notebook फ़ाइलों पर धीमा हो सकता है | स्थानीय संपादक जैसा प्रदर्शन |
| डिबगिंग | सीमित डिबगिंग क्षमताएँ | IDE के पूरे डिबगिंग औज़ार |
| निर्यात विकल्प | HTML, PDF और अन्य प्रारूप | extension के जरिए वही क्षमताएँ |
| सहयोग | संस्करण नियंत्रण के साथ चुनौतीपूर्ण | सामान्य कोड सहयोग कार्यप्रवाह |
| निर्भरताएँ | अलग परिवेश फ़ाइलों में प्रबंधित | परिवेश के भीतर एकीकृत प्रबंधन |
| छिपी हुई स्थिति की समस्या | out-of-order execution के कारण आम | क्रम से चलाने की प्रवृत्ति के कारण कम |
| Markdown समर्थन | मूल रूप से उपलब्ध | cell markers के माध्यम से, लगभग वही क्षमता |
| टाइप जाँच | नहीं के बराबर | IDE का पूरा स्थिर विश्लेषण समर्थन |
| एक्सटेंशन तंत्र | Jupyter extensions | IDE extensions + Jupyter extensions |
यह तुलना साफ़ दिखाती है कि गंभीर डेटा विश्लेषण कार्य के लिए, ख़ासकर तब जब आप कृत्रिम बुद्धिमत्ता क्षमताओं का लाभ लेना चाहते हों और कार्यप्रवाह को टूटने नहीं देना चाहते हों, Cursor IDE वाला तरीका कई मायनों में अधिक शक्तिशाली है।
Jupyter की वास्तुकला और क्षमताओं के बारे में अधिक विस्तार से समझने के लिए Project Jupyter Documentation देखें, जिसमें पूरे Jupyter पारिस्थितिकी तंत्र का व्यापक परिचय दिया गया है।
वीडियो ट्यूटोरियल: Cursor IDE में पूरा Jupyter कार्यप्रवाह देखें
अगर आप देखकर सीखना पसंद करते हैं, तो मैंने इस लेख की सभी बातों को समेटता हुआ एक विस्तृत वीडियो ट्यूटोरियल भी बनाया है:

इस वीडियो में Cursor IDE के साथ Jupyter Notebooks की व्यवस्था करना, कृत्रिम बुद्धिमत्ता एकीकरण का उपयोग करना, दृश्यांकन बनाना और परिणाम निर्यात करना, सब कुछ वास्तविक समय में दिखाया गया है। आप देख पाएँगे कि यह एकीकरण व्यवहार में कैसे काम करता है, और यह भी कि एक ही परिवेश में रहते हुए पूरा कार्यप्रवाह कितना सहज हो सकता है।