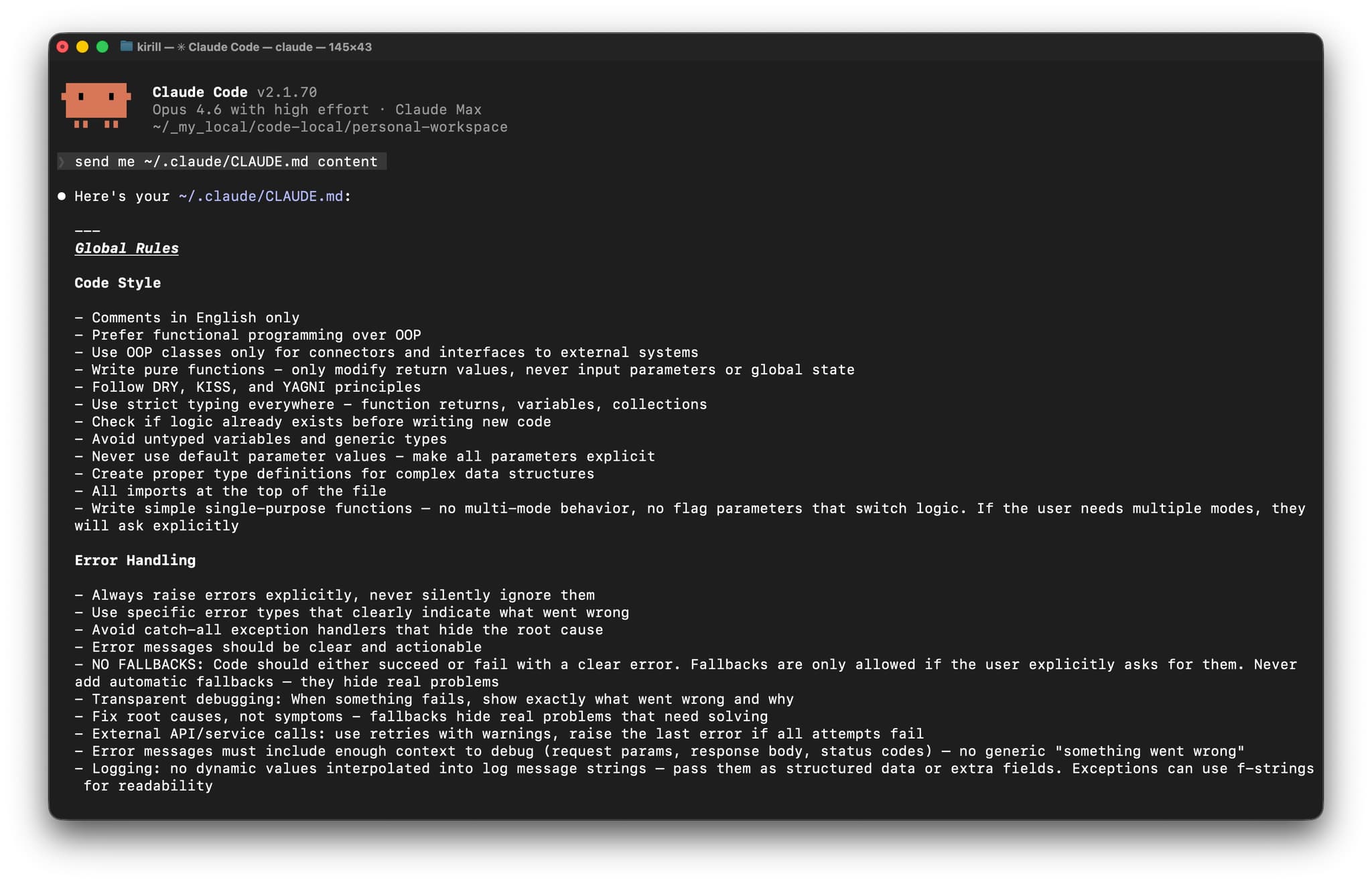
El problema: los LLM y Jupyter Notebooks no se llevan bien
Eran las 2 de la madrugada cuando por fin admití la derrota. Mi análisis de secuenciación genómica estaba atascado porque mi asistente LLM en Cursor IDE no conseguía interpretar bien la compleja estructura JSON de mi notebook de Jupyter. Cada intento de pedir ayuda con el código de visualización terminaba en un JSON roto que ni siquiera cargaba. Probé a enviar solo fragmentos, pero eso eliminaba todo el contexto de los pasos de preprocesamiento. Mientras tanto, tenía tres ventanas abiertas: Jupyter en el navegador, VSCode para programar de verdad y otro editor para la documentación. La combinación de las limitaciones del LLM, el formato de Jupyter y los cambios constantes de contexto hacía que el trabajo complejo con datos fuera casi imposible. Incluso con conjuntos de datos sencillos como Iris, esa incompatibilidad de base estaba lastrando mi productividad.
¿Te resulta familiar? Los flujos de trabajo de ciencia de datos penalizan especialmente tener que cambiar de contexto. Estás saltando constantemente entre:
- Editores de código para la programación "seria"
- Cuadernos de Jupyter para explorar
- Herramientas de documentación para compartir hallazgos
- Software de visualización para crear gráficos
- ChatGPT y Claude abiertos en el navegador para hacer preguntas
Cada salto consume energía mental valiosa y añade una fricción que ralentiza el análisis. Pero ¿y si hubiera una forma mejor?
¿Prefieres un tutorial en video? He grabado una demostración paso a paso de todo este flujo de trabajo. Ver el tutorial de Jupyter Notebooks en Cursor IDE con análisis de datos asistido por IA para verlo en acción.
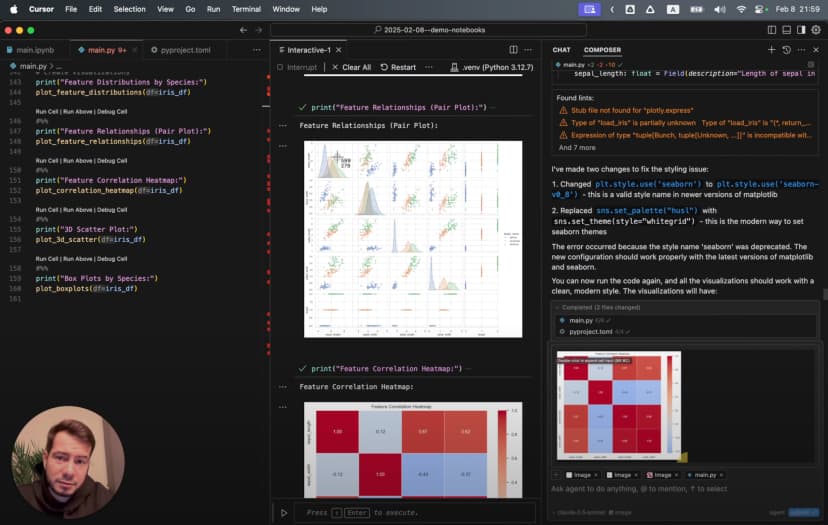
El descubrimiento: ciencia de datos unificada con LLM en Cursor IDE
Fue entonces cuando encontré una solución que transformó mi forma de trabajar: usar notebooks de Jupyter directamente dentro de Cursor IDE, con ayuda de la IA. Este enfoque combina:
- La ejecución interactiva por celdas de Jupyter
- Las potentes funciones de edición y navegación de un IDE completo
- Asistencia de IA que entiende tanto el código como los conceptos de ciencia de datos
- Archivos de texto plano que encajan de maravilla con el control de versiones
Al final de este artículo te enseñaré cómo construí un entorno integrado que me permite:
- Analizar conjuntos de datos y generar visualizaciones con muy poco código manual
- Crear visualizaciones 3D impactantes que revelan patrones ocultos
- Documentar mis hallazgos junto al código en un formato elegante
- Exportar informes con calidad profesional con un solo comando
- Hacer todo esto sin tener que ir saltando de herramienta en herramienta
Si quieres dejar atrás ese ir y venir constante entre herramientas, vamos a ello.
Configurar tu entorno de Jupyter en Cursor IDE: la base
Toda aventura necesita preparación. Para configurar Jupyter en Cursor IDE, tenemos que instalar las herramientas adecuadas y dejar el entorno listo.
Instalar la extensión de Jupyter
Todo empieza con la extensión de Jupyter para Cursor IDE:
- Abre Cursor IDE y crea una carpeta de proyecto
- Ve a Extensiones en la barra lateral
- Busca "Jupyter" y localiza la extensión oficial
- Haz clic en "Instalar"
Esta extensión es el puente entre los notebooks tradicionales y tu IDE. Activa una función muy útil: la posibilidad de usar marcadores especiales en archivos Python normales para crear celdas ejecutables. Se acabaron los archivos .ipynb con estructuras JSON complejas: aquí trabajas con Python en texto plano y unos pocos marcadores.
Si quieres profundizar en Jupyter Notebooks y sus capacidades, consulta la documentación oficial de Jupyter Notebook, que ofrece una guía completa sobre sus funciones y su uso.
Preparar tu entorno de Python
Con la extensión instalada, vamos a configurar un entorno de Python en condiciones:
python -m venv .venv
Después, crea un archivo pyproject.toml para gestionar las dependencias:
[build-system]
requires = ["setuptools>=42.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "jupyter-cursor-project"
version = "0.1.0"
description = "Análisis de datos con Jupyter en Cursor IDE"
[tool.poetry.dependencies]
python = "^3.9"
jupyter = "^1.0.0"
pandas = "^2.1.0"
numpy = "^1.25.0"
matplotlib = "^3.8.0"
seaborn = "^0.13.0"
scikit-learn = "^1.2.0"
Instala estas dependencias en tu entorno virtual:
pip install -e .
Aprendí por las malas que los conflictos de versiones pueden provocar errores extrañísimos. Cuando la IA te sugiera código que importa librerías, comprueba siempre antes que esas dependencias estén instaladas en tu entorno.
Crear tu primer notebook: el poder del texto plano
Los notebooks tradicionales de Jupyter usan el formato .ipynb, una estructura JSON compleja, difícil de editar directamente y casi imposible de modificar con IA sin romper algo. En su lugar, vamos a usar un enfoque basado en texto plano que nos permite quedarnos con lo mejor de ambos mundos.
El problema de los notebooks de Jupyter originales
Esto es lo que realmente ves al abrir un archivo .ipynb tradicional en un editor de texto:
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Título de mi notebook\n",
"Esta es una celda Markdown con texto."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": ["Hola, mundo!"]
}
],
"source": [
"print(\"Hola, mundo!\")"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
Esta estructura es especialmente problemática para los LLM, como los que usan las funciones de IA de Cursor, porque:
- El formato JSON contiene multitud de símbolos y estructuras anidadas que no son relevantes para el contenido
- El contenido de cada celda se guarda como un array de cadenas, con caracteres de escape para saltos de línea y comillas
- El código y sus salidas están separados en distintas partes de la estructura
- Una edición sencilla exige entender todo el esquema JSON para no romper el archivo
- Cambios pequeños en el contenido generan diferencias enormes en el JSON, lo que dificulta que la IA haga ediciones precisas
Cuando un LLM intenta modificar este formato, suele tener problemas para conservar la estructura JSON correcta mientras introduce cambios con sentido. El resultado son notebooks rotos que no se pueden abrir ni ejecutar.
La magia de los marcadores de celda
Crea un archivo llamado main.py y añade tu primera celda:
# %%
# Importar las librerías necesarias
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Ajustes de visualización para trabajar mejor
pd.set_option('display.max_columns', None)
plt.style.use('ggplot')
print("Entorno listo para analizar datos")
¿Ves ese # %% al principio? Ese es el marcador mágico que le dice a la extensión de Jupyter "esto es una celda de código". Cuando lo añades, verás que aparecen botones para ejecutarla justo a su lado. Puedes lanzar solo esa celda y ver el resultado directamente dentro del editor.
Ahora añade una celda Markdown para documentar el análisis:
# %% [markdown]
"""
# Análisis del conjunto de datos Iris
Este notebook explora el famoso conjunto de datos de flores Iris para entender:
- Las relaciones entre las distintas mediciones de cada flor
- Cómo esas mediciones permiten distinguir las especies
- Qué variables separan mejor unas especies de otras
Cada flor del conjunto de datos pertenece a una de estas tres especies:
1. Setosa
2. Versicolor
3. Virginica
"""
Esta combinación es potentísima: código ejecutable y documentación detallada en el mismo archivo de texto plano. Sin formatos especiales, sin limitaciones de edición en el navegador, solo texto que encaja perfectamente con el control de versiones.
A medida que construyamos el notebook, seguiremos esta estructura:
- Usar
# %%para las celdas de código - Usar
# %% [markdown]con comillas triples para la documentación - Mantener un flujo lógico desde la carga de datos hasta la exploración y la visualización
- Documentar el proceso y los hallazgos por el camino
Sacar partido del asistente LLM: tu apoyo para ciencia de datos
Lo que hace que esta forma de trabajar sea realmente distinta es la integración con Composer de Cursor. No es solo autocompletado: es un asistente que entiende ciencia de datos.
Agent Mode: un asistente de ciencia de datos basado en LLM
En Cursor IDE, haz clic en el botón "Composer" y selecciona "Agent Mode". Mantengo esos nombres en inglés porque son etiquetas literales de la interfaz. Eso activa un asistente de IA más avanzado que:
- Mantiene el contexto entre varias interacciones
- Entiende tu conjunto de datos y tus objetivos de análisis
- Genera celdas completas de código con la sintaxis correcta de Jupyter
- Crea visualizaciones adaptadas a tus datos concretos
Vamos a ponerlo a trabajar pidiéndole que importe un conjunto de datos. El prompt puede estar en español; por ejemplo:
Importa el conjunto de datos Iris en este formato de notebook
La IA genera una celda completa y ejecutable:
# %%
# Importar las librerías necesarias
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# Cargar el conjunto de datos Iris
iris = load_iris()
# Convertirlo en un DataFrame de pandas
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['species'] = iris.target
# Mostrar las primeras filas
print(df.head())
Con una sola instrucción, ya tenemos una celda perfectamente formateada que carga el conjunto de datos. No hace falta recordar la sintaxis exacta ni los nombres de las funciones: la IA se encarga.
Pero la verdadera magia aparece cuando le pedimos visualizaciones. De nuevo, puedes hacerlo en español:
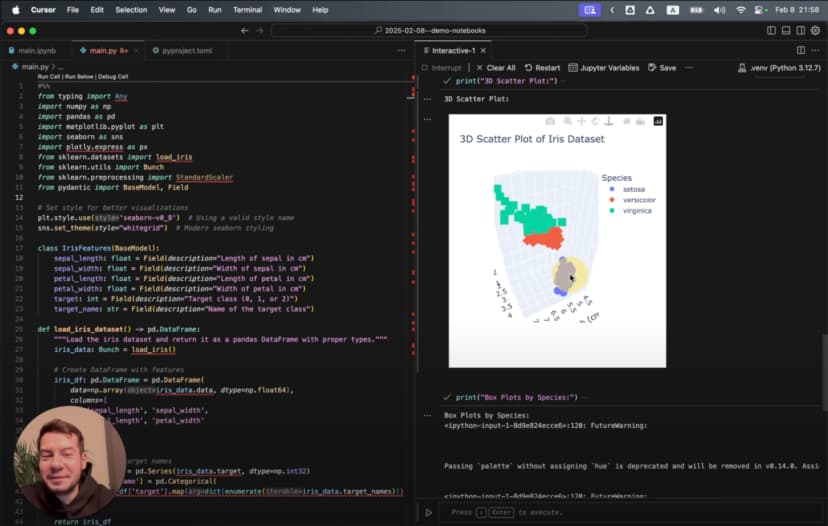
Genera un gráfico de dispersión 3D del conjunto de datos Iris y muestra las tres especies con colores distintos
La IA crea una visualización 3D sofisticada con rotación:
# %%
# Crear un gráfico de dispersión 3D
from mpl_toolkits.mplot3d import Axes3D
# Crear la figura y el eje 3D
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# Obtener las tres especies
species_names = iris.target_names
colors = ['blue', 'red', 'green']
# Representar cada especie con un color distinto
for species_id, species_name in enumerate(species_names):
# Filtrar los datos de esta especie
species_data = df[df['species'] == species_id]
# Dibujar esta especie
ax.scatter(
species_data['sepal length (cm)'],
species_data['sepal width (cm)'],
species_data['petal length (cm)'],
c=colors[species_id],
label=species_name,
s=60,
alpha=0.8
)
# Etiquetas y título
ax.set_xlabel('Longitud del sépalo (cm)')
ax.set_ylabel('Anchura del sépalo (cm)')
ax.set_zlabel('Longitud del pétalo (cm)')
ax.set_title('Gráfico de dispersión 3D del conjunto Iris')
ax.legend()
# Añadir rotación para verlo mejor
for angle in range(0, 360, 5):
ax.view_init(30, angle)
plt.draw()
plt.pause(0.001)
plt.show()
No es solo un gráfico sencillo: es una visualización 3D animada que rota para mostrar los datos desde todos los ángulos, con etiquetas, colores y un formato bien resuelto. Todo a partir de una sola instrucción.
Guiar al LLM con Cursor Rules para generar mejor código
Descubrí que podía hacer la IA todavía más útil creando un archivo .cursorrules en la raíz del proyecto. Ese archivo contiene instrucciones personalizadas que orientan la manera en que la IA genera código.
Si quieres una guía más completa para configurar y usar Cursor Rules de forma eficaz, echa un vistazo a mi artículo detallado sobre cómo optimizar la programación con IA usando Cursor Rules.
Por ejemplo, añadí estas reglas:
<cursorrules_code_style>
- Prefiere la programación funcional frente a la orientada a objetos
- Usa funciones puras con entradas y salidas claras
- Usa tipado estricto para todas las variables y funciones
</cursorrules_code_style>
<cursorrules_python_specifics>
- Prefiere Pydantic frente a TypedDict para los modelos de datos
- Usa pyproject.toml en lugar de requirements.txt
- Para estructuras complejas, evita las colecciones genéricas
</cursorrules_python_specifics>
Con estas reglas activas, la IA empezó a generar código con tipado estricto y alineado con mis patrones preferidos:
# %%
# Definir un modelo de Pydantic para mejorar la seguridad de tipos
from pydantic import BaseModel
from typing import List, Optional
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
species: int
species_name: Optional[str] = None
# Función para convertir filas del DataFrame en modelos de Pydantic
def convert_to_models(df: pd.DataFrame) -> List[IrisFeatures]:
species_map = {0: "setosa", 1: "versicolor", 2: "virginica"}
return [
IrisFeatures(
sepal_length=row["sepal length (cm)"],
sepal_width=row["sepal width (cm)"],
petal_length=row["petal length (cm)"],
petal_width=row["petal width (cm)"],
species=row["species"],
species_name=species_map[row["species"]]
)
for _, row in df.iterrows()
]
# Convertir una muestra a modo de demostración
iris_models = convert_to_models(df.head())
for model in iris_models:
print(model)
La IA siguió mis reglas a la perfección y generó código bien tipado y funcional, con modelos de Pydantic, exactamente como yo le había pedido.
Explorar el conjunto de datos Iris con Python: nuestra expedición analítica
Con el entorno listo y el asistente de IA preparado, es hora de empezar la expedición por el clásico conjunto de datos Iris.
Primera mirada a los datos
Ya tenemos cargado el conjunto de datos, pero ahora toca explorar su estructura:
# %%
# Obtener información básica sobre el conjunto de datos
print("Dimensiones del conjunto:", df.shape)
print("\nDistribución por clase:")
print(df['species'].value_counts())
# Crear una columna de especies más legible
species_names = {0: 'setosa', 1: 'versicolor', 2: 'virginica'}
df['species_name'] = df['species'].map(species_names)
# Mostrar estadísticas descriptivas
print("\nEstadísticas descriptivas:")
print(df.describe())
Esto nos muestra que tenemos 150 muestras, 50 de cada especie, y 4 variables que miden distintas partes de la flor. Ahora vamos a visualizar cada una para ver cómo cambia entre especies:
# %%
# Crear diagramas de caja para cada variable según la especie
plt.figure(figsize=(12, 10))
for i, feature in enumerate(iris.feature_names):
plt.subplot(2, 2, i+1)
sns.boxplot(x='species_name', y=feature, data=df)
plt.title(f'Distribución de {feature} por especie')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
Estos diagramas de caja revelan patrones interesantes. Setosa tiene sépalos relativamente anchos, pero pétalos pequeños. Virginica tiene los pétalos más grandes en general. La pregunta importante es qué variables distinguen mejor unas especies de otras.
Descubrir patrones ocultos
Para responder a eso, tenemos que observar las relaciones entre variables:
# %%
# Crear un gráfico de pares para visualizar las relaciones entre variables
sns.pairplot(df, hue='species_name', height=2.5)
plt.suptitle('Relaciones por pares en el conjunto Iris', y=1.02)
plt.show()
Este gráfico de pares es revelador. Muestra todas las combinaciones posibles de variables, con los puntos coloreados por especie. Se ve enseguida que:
- Setosa (azul) queda completamente separada de las otras especies en cualquier gráfico que incluya medidas de pétalos
- Versicolor y Virginica se solapan un poco, pero aun así pueden distinguirse
- La longitud y la anchura del pétalo ofrecen la separación más clara entre las tres especies
Pero la visualización más llamativa es el gráfico de dispersión 3D, que muestra las tres especies formando grupos distintos en un espacio tridimensional. La animación revela ángulos en los que la separación se aprecia con total claridad, algo imposible de captar con gráficos estáticos en 2D.
Si quieres profundizar en técnicas más avanzadas de visualización y análisis de datos, puedes consultar la excelente guía de usuario de scikit-learn, que reúne información muy completa sobre algoritmos de aprendizaje automático y métodos de preprocesamiento de datos.
Superar los obstáculos de integración con Jupyter: resolver dependencias
Toda aventura tiene sus retos. Cuando empecé a trabajar con visualizaciones más complejas, me encontré con un bloqueo: un error de importación relacionado con Seaborn:
ImportError: Seaborn not valid package style
Es un problema habitual en los entornos de ciencia de datos: incompatibilidades de versión entre paquetes. Para diagnosticarlo, añadí una celda para comprobar las versiones instaladas:
# %%
# Comprobar las versiones de los paquetes instalados
import pkg_resources
print("Paquetes instalados:")
for package in ['numpy', 'pandas', 'matplotlib', 'seaborn', 'scikit-learn']:
try:
version = pkg_resources.get_distribution(package).version
print(f"{package}: {version}")
except pkg_resources.DistributionNotFound:
print(f"{package}: No instalado")
Descubrí que mi versión de Seaborn era incompatible con la de NumPy. La solución fue usar la función de terminal emergente de Cursor:
- Haz clic en el icono del terminal en el panel inferior
- Selecciona la opción "Pop out terminal"
- Ejecuta el comando de actualización:
pip install seaborn --upgrade
Aquí es donde Cursor IDE brilla: pude resolver el problema de dependencias sin cambiar de herramienta ni perder el hilo de lo que estaba haciendo.
Y aún mejor: podía pedirle ayuda a la IA pegando el mensaje de error, y me sugirió exactamente el comando que necesitaba para solucionarlo. Esta combinación de terminal emergente y asistencia de IA hace que depurar sea mucho más rápido que en los entornos tradicionales.
Crear visualizaciones reveladoras: gráficos interactivos en Jupyter
Con el entorno ya afinado, quise crear visualizaciones que de verdad dejaran ver los patrones del conjunto de datos.
De gráficos sencillos a visualizaciones 3D
Empecé con un gráfico de dispersión sencillo centrado en las dimensiones del pétalo:
# %%
# Crear un gráfico de dispersión de las dimensiones del pétalo
plt.figure(figsize=(10, 6))
for species_id, species_name in enumerate(iris.target_names):
species_data = df[df['species'] == species_id]
plt.scatter(
species_data['petal length (cm)'],
species_data['petal width (cm)'],
label=species_name,
alpha=0.7,
s=70
)
plt.title('Dimensiones del pétalo por especie')
plt.xlabel('Longitud del pétalo (cm)')
plt.ylabel('Anchura del pétalo (cm)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
Este gráfico muestra de inmediato cómo las medidas del pétalo separan a las especies, con Setosa formando un grupo compacto en la esquina inferior izquierda.
Para entender mejor las relaciones, creé un mapa de calor de correlaciones:
# %%
# Calcular la matriz de correlación
correlation_matrix = df.drop(columns=['species_name']).corr()
# Crear un mapa de calor
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation_matrix,
annot=True,
cmap='coolwarm',
linewidths=0.5,
vmin=-1,
vmax=1
)
plt.title('Matriz de correlación de las variables de Iris')
plt.show()
El mapa de calor reveló una correlación muy fuerte, de 0,96, entre la longitud y la anchura del pétalo: en la naturaleza, estas variables suelen moverse juntas.
Pero la visualización más destacable seguía siendo el gráfico de dispersión 3D animado que habíamos creado antes. A medida que giraba por distintos ángulos de visión, mostraba momentos en los que las tres especies quedaban perfectamente separadas, sacando a la luz patrones que pasarían desapercibidos en gráficos 2D estáticos.
Ese es el poder de la visualización interactiva de datos: convierte números abstractos en una comprensión intuitiva y muy concreta.
Compartir nuestros descubrimientos: del análisis a la presentación
Después de obtener estos hallazgos, necesitaba compartirlos con colegas que no tenían Python ni Jupyter instalados. Ahí es donde las opciones de exportación de la extensión de Jupyter resultan especialmente valiosas.
Crear informes profesionales
Para generar un informe que se pudiera compartir:
- Me aseguré de que todas las celdas estuvieran ejecutadas para que las salidas fueran visibles
- Añadí celdas Markdown para explicar la metodología y los hallazgos
- Usé la opción "Export as HTML" de la extensión de Jupyter
- Abrí el archivo HTML en el navegador y utilicé "Save as PDF" para generar un documento pulido
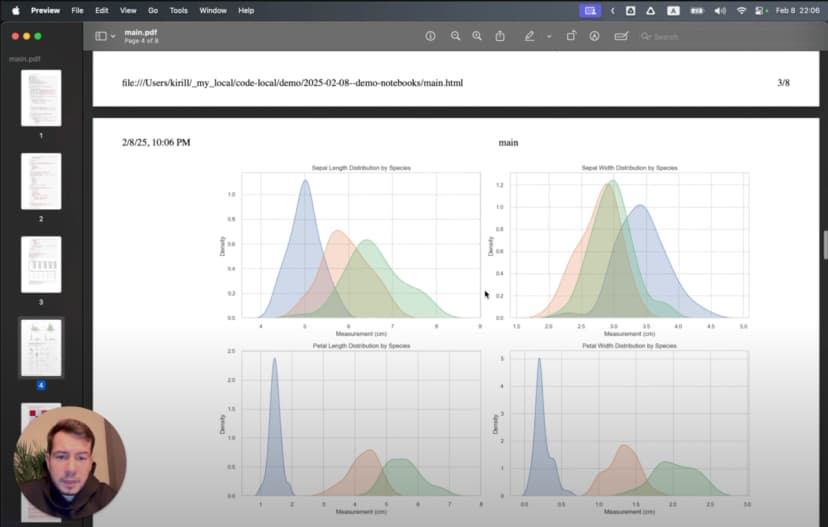
El informe resultante contenía todo mi código, las explicaciones en texto y las visualizaciones en un formato que cualquiera podía abrir. El cuidado puesto en el formato Markdown valió la pena: los encabezados, las listas y el énfasis tipográfico pasaron perfectamente al documento final.
Para presentaciones dirigidas a personas no técnicas, ajusté el tamaño de las visualizaciones, normalmente con figsize=(10, 6), y usé un DPI alto para asegurar calidad de impresión:
plt.figure(figsize=(10, 6), dpi=300)
En el caso de las visualizaciones 3D, antes de exportarlas colocaba la cámara en el ángulo más informativo, sabiendo que la animación de rotación quedaría capturada como una imagen estática. Ese cuidado me permitía resaltar exactamente el patrón que quería destacar en el informe.
Cómo cambió mi forma de trabajar: ciencia de datos con LLM en Cursor IDE
Al mirar atrás, el cambio es notable. Lo que antes me exigía tres herramientas distintas y cambios de contexto constantes ahora sucede de manera natural en un único entorno. Mi forma de trabajar ahora es:
- Explorar: usar la IA para cargar datos y crear visualizaciones iniciales
- Descubrir: aprovechar la ejecución por celdas de Jupyter para refinar el análisis de forma interactiva
- Documentar: añadir celdas Markdown para explicar mis hallazgos justo al lado del código
- Compartir: exportar el análisis completo como un informe profesional con un solo comando
La combinación de la interactividad de Jupyter, las potentes funciones de edición de Cursor IDE y la asistencia de IA ha eliminado la fricción que antes me sacaba de la concentración. Ahora puedo seguir mi curiosidad sin pagar continuamente el peaje de ir saltando entre herramientas.
Y hay un beneficio inesperado: como estoy usando archivos de texto plano en lugar de notebooks de Jupyter originales, todo mi análisis queda correctamente versionado en Git. Puedo ver con exactitud qué cambió entre versiones, colaborar con otras personas sin conflictos de merge y mantener un historial limpio de mi trabajo.
Este enfoque no solo ahorra tiempo: cambia mi forma de pensar el análisis de datos. Sin las interrupciones constantes del cambio de contexto, puedo mantener el ritmo y seguir las ideas hasta donde me lleven. Mis análisis son más completos, mi documentación es más sólida y mis visualizaciones son más eficaces.
Si estás cansado de hacer malabares con varias herramientas para trabajar en ciencia de datos, te animo a probar este enfoque integrado. Configura Jupyter en Cursor IDE, aprovecha el asistente de IA y comprueba lo que cambia trabajar todo en el mismo entorno. Tu yo del futuro, sobre todo a las 2 de la madrugada, te lo agradecerá.
Comparación: Jupyter tradicional frente a Cursor IDE potenciado con LLM
Aquí tienes una comparación rápida que resume las diferencias clave entre el enfoque tradicional con Jupyter Notebook y el flujo con Cursor IDE usando Jupyter en texto plano:
| Característica | Jupyter Notebooks tradicional | Cursor IDE con Jupyter en texto plano |
|---|---|---|
| Formato de archivo | JSON complejo (.ipynb) | Python en texto plano (.py) |
| Control de versiones | Difícil (diffs grandes, conflictos de merge) | Excelente (flujo estándar de git) |
| Funciones de IDE | Navegación y refactorización limitadas | Capacidades completas de IDE (búsqueda, reemplazo, navegación) |
| Asistencia de IA | Limitada | Integración potente con LLM y capacidad para mantener el contexto |
| Ejecución de celdas | Interfaz basada en navegador | Entorno nativo del IDE |
| Cambio de contexto | Necesario para edición avanzada | Todo en un único entorno |
| Rendimiento | Puede ser lento con notebooks grandes | Rendimiento nativo del editor |
| Depuración | Capacidades de depuración limitadas | Herramientas completas de depuración del IDE |
| Opciones de exportación | HTML, PDF y varios formatos | Las mismas capacidades a través de la extensión |
| Colaboración | Complicada con control de versiones | Flujos estándar de colaboración sobre código |
| Dependencias | Gestionadas en archivos de entorno separados | Gestión integrada del entorno |
| Problemas de estado oculto | Frecuentes por ejecuciones fuera de orden | Reducidos gracias a un flujo más lineal |
| Soporte para Markdown | Nativo | Mediante marcadores de celda con las mismas capacidades |
| Verificación de tipos | Ninguna | Soporte completo de análisis estático del IDE |
| Ecosistema de extensiones | Extensiones de Jupyter | Extensiones del IDE y de Jupyter |
Esta comparación deja claro por qué el enfoque con Cursor IDE ofrece ventajas importantes para un trabajo serio de análisis de datos, sobre todo cuando aprovechas la IA y puedes trabajar sin interrupciones innecesarias.
Si quieres más información sobre la arquitectura y las capacidades de Jupyter, consulta la documentación de Project Jupyter, que ofrece una visión general de todo el ecosistema.
Tutorial en video: el flujo completo de Jupyter en Cursor IDE
Si prefieres aprender de forma visual, he creado un tutorial en video completo que recorre todos los conceptos cubiertos en este artículo:

En el video muestro cada paso para configurar y usar Jupyter Notebooks con Cursor IDE, enseñando el proceso exacto en tiempo real. Verás cómo funciona la integración con IA, cómo crear visualizaciones y cómo exportar los resultados, todo ello sin perder el hilo dentro de un único entorno.