من الإحباط إلى التدفق: رحلتي مع Jupyter Notebooks وLLM داخل Cursor IDE
المشكلة: نماذج اللغة وJupyter Notebooks لا تعمل معًا بسلاسة
كانت الساعة الثانية صباحًا عندما اعترفت أخيرًا بالهزيمة. كان تحليل التسلسل الجيني الذي أعمل عليه متوقفًا لأن مساعد LLM داخل Cursor IDE لم يكن قادرًا على فهم البنية المعقدة لملف Jupyter notebook المكتوب بصيغة JSON. كل مرة أطلب فيها مساعدة في كود التصور البصري، كانت النتيجة ملف JSON مكسورًا لا يمكن فتحه أصلًا. حاولت أن أرسل مقتطفات فقط، لكن ذلك كان يضيع سياق خطوات المعالجة المسبقة. وفي الوقت نفسه كنت أعمل بين ثلاث نوافذ: Jupyter في المتصفح، وVSCode للبرمجة “الحقيقية”، ومحرر آخر للتوثيق. مزيج قيود LLM مع صيغة Jupyter وتبديل السياق المستمر كان يجعل العمل المعقد على البيانات شبه مستحيل. وحتى مع بيانات أبسط مثل Iris، كانت هذه المشكلة الأساسية تخنق إنتاجيتي.
هل يبدو ذلك مألوفًا؟ سير عمل علم البيانات قاسٍ جدًا في موضوع تبديل السياق. فأنت تتنقل باستمرار بين:
- محررات الشيفرة للبرمجة الجدية
- Jupyter notebooks للاستكشاف
- أدوات التوثيق لمشاركة النتائج
- برامج التصور لإنشاء الرسوم
- ChatGPT وClaude المفتوحين في المتصفح
كل انتقال يستهلك طاقة ذهنية ويضيف احتكاكًا يبطئ عملية الاكتشاف. لكن ماذا لو كانت هناك طريقة أفضل؟
تفضل فيديو؟ أنشأت شرحًا خطوة بخطوة لهذا المسار كاملًا. شاهد Jupyter Notebooks in Cursor IDE Tutorial with AI-Powered Data Analysis لترى الأسلوب أثناء التطبيق.
الاكتشاف: توحيد سير عمل علم البيانات داخل Cursor IDE
حينها صادفت حلًا غيّر طريقة عملي: استخدام Jupyter notebooks مباشرة داخل Cursor IDE مع دعم الذكاء الاصطناعي. هذا الأسلوب يجمع بين:
- التنفيذ التفاعلي المعتمد على الخلايا في Jupyter
- ميزات التحرير والتنقل الموجودة في IDE حقيقي
- مساعدة AI تفهم الشيفرة ومفاهيم علم البيانات معًا
- ملفات نصية عادية تتعامل جيدًا مع version control
بحلول نهاية هذه المقالة سترى كيف أنشأت بيئة موحدة تسمح لي بأن:
- أحلل البيانات وأنشئ الرسوم بأقل قدر من الترميز اليدوي
- أبني تصورات ثلاثية الأبعاد تكشف أنماطًا مخفية
- أوثق نتائجي بجانب الشيفرة نفسها
- أصدّر تقارير احترافية بأمر واحد
- أفعل كل ذلك من دون التنقل المستمر بين الأدوات
إعداد بيئة Jupyter داخل Cursor IDE
أي رحلة جيدة تبدأ بتحضير مناسب. لكي نستخدم Jupyter داخل Cursor IDE، علينا تثبيت الأدوات الصحيحة وتجهيز البيئة.
تثبيت إضافة Jupyter
البداية مع إضافة Jupyter:
- افتح Cursor IDE وأنشئ مجلد مشروع
- اذهب إلى Extensions في الشريط الجانبي
- ابحث عن “Jupyter” واختر الإضافة الرسمية
- اضغط “Install”
هذه الإضافة هي الجسر بين notebooks التقليدية والـ IDE. وهي تتيح ميزة مهمة جدًا: استخدام علامات خاصة داخل ملفات Python العادية لإنشاء خلايا قابلة للتنفيذ. لم تعد مضطرًا للعمل مع ملفات .ipynb المعقدة، بل يمكنك استخدام Python نصي بسيط.
إذا أردت معرفة المزيد عن Jupyter Notebook نفسه، فراجع الوثائق الرسمية.
تجهيز بيئة Python
بعد تثبيت الإضافة، الخطوة التالية هي بناء بيئة Python نظيفة:
python -m venv .venv
ثم أنشئ ملف pyproject.toml لإدارة الاعتماديات:
[build-system]
requires = ["setuptools>=42.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "jupyter-cursor-project"
version = "0.1.0"
description = "Data analysis with Jupyter in Cursor IDE"
[tool.poetry.dependencies]
python = "^3.9"
jupyter = "^1.0.0"
pandas = "^2.1.0"
numpy = "^1.25.0"
matplotlib = "^3.8.0"
seaborn = "^0.13.0"
scikit-learn = "^1.2.0"
ثم ثبّت الاعتماديات:
pip install -e .
تعلمت بالطريقة الصعبة أن تضارب الإصدارات يسبب أخطاء غامضة. عندما تقترح عليك AI كودًا يستورد مكتبات، تأكد أولًا أنها مثبتة في بيئتك.
إنشاء أول Notebook: قوة النص العادي
ملفات Jupyter التقليدية تستخدم .ipynb، وهي بنية JSON معقدة يصعب تحريرها يدويًا، ويصعب أكثر أن تعدلها AI من دون كسرها. لذلك سنستخدم نهج النص العادي.
المشكلة في ملفات Jupyter الأصلية
هذا مثال مبسط لشكل ملف .ipynb داخل محرر نصوص:
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# My Notebook Title\n",
"This is a markdown cell with text."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": ["Hello, world!"]
}
],
"source": [
"print(\"Hello, world!\")"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
هذه البنية صعبة على نماذج اللغة لعدة أسباب:
- صيغة JSON مليئة برموز وطبقات لا تمثل المحتوى الفعلي
- محتوى كل خلية مخزن كمصفوفة نصوص مع escape characters
- الكود والمخرجات منفصلان في أماكن مختلفة
- أي تعديل صغير يتطلب الحفاظ على البنية كاملة
- تغييرات صغيرة في المحتوى تنتج فروقات كبيرة في الملف
لهذا السبب كثيرًا ما تكسر LLM صيغة الملف أثناء التعديل.
سحر علامات الخلايا
أنشئ ملفًا باسم main.py وأضف أول خلية:
# %%
# Import necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Display settings for better visualization
pd.set_option('display.max_columns', None)
plt.style.use('ggplot')
print("Environment ready for data analysis!")
العلامة # %% هي المفتاح. إضافة Jupyter تفهمها على أنها بداية خلية كود، وعندها ستظهر أزرار التشغيل بجانبها.
ثم أضف خلية markdown:
# %% [markdown]
"""
# Iris Dataset Analysis
This notebook explores the famous Iris flower dataset to understand:
- The relationships between different flower measurements
- How these measurements can distinguish between species
- Which features provide the best separation between species
Each flower in the dataset belongs to one of three species:
1. Setosa
2. Versicolor
3. Virginica
"""
هذه التركيبة قوية جدًا: كود قابل للتنفيذ وتوثيق غني في ملف نصي واحد، من دون صيغ خاصة معقدة.
إطلاق مساعد LLM
ما يجعل هذا المسار ثوريًا فعلًا هو الدمج مع Cursor Composer. هو ليس مجرد autocomplete، بل شريك يمكنه التعاون.
Agent Mode: رفيق علم بيانات مدعوم بالذكاء الاصطناعي
داخل Cursor IDE اضغط “Composer” ثم اختر “Agent Mode”. هذا يفعّل مساعدًا أكثر ذكاءً يمكنه:
- الحفاظ على السياق عبر عدة تفاعلات
- فهم البيانات وأهداف التحليل
- إنشاء خلايا كاملة بصيغة Jupyter الصحيحة
- بناء تصورات مناسبة لبياناتك
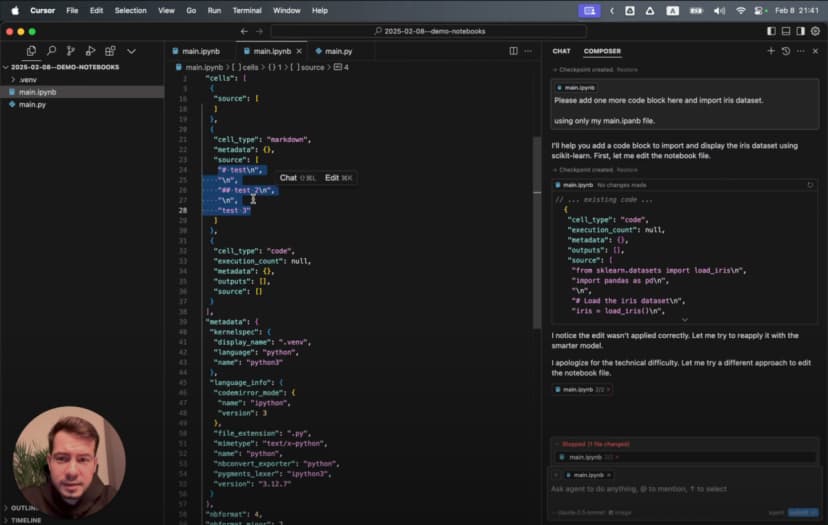
لنطلب منه أولًا استيراد البيانات:
Please import the Iris dataset in this notebook format
سيولّد خلية كاملة قابلة للتنفيذ:
# %%
# Import necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
# Convert to pandas DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['species'] = iris.target
# Display the first few rows
print(df.head())
مجرد طلب واحد، ولدينا خلية جاهزة.
وعندما طلبت منه إنشاء تصور ثلاثي الأبعاد:
Generate a 3D scatter plot for the iris dataset showing the three species in different colors
أنشأ تصورًا متقدمًا:
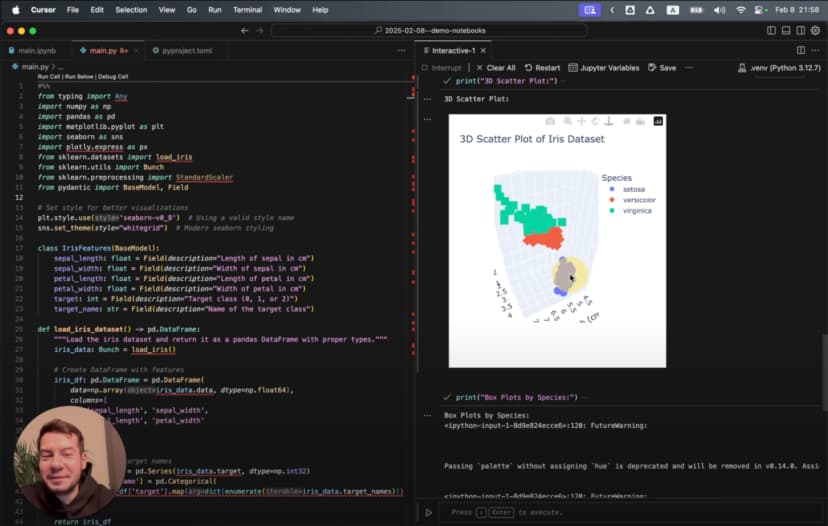
# %%
# Create 3D scatter plot
from mpl_toolkits.mplot3d import Axes3D
# Create figure and 3D axis
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# Get the three species
species_names = iris.target_names
colors = ['blue', 'red', 'green']
# Plot each species with a different color
for species_id, species_name in enumerate(species_names):
# Filter data for this species
species_data = df[df['species'] == species_id]
# Plot this species
ax.scatter(
species_data['sepal length (cm)'],
species_data['sepal width (cm)'],
species_data['petal length (cm)'],
c=colors[species_id],
label=species_name,
s=60,
alpha=0.8
)
# Set labels and title
ax.set_xlabel('Sepal Length (cm)')
ax.set_ylabel('Sepal Width (cm)')
ax.set_zlabel('Petal Length (cm)')
ax.set_title('3D Scatter Plot of Iris Dataset')
ax.legend()
# Add rotation for better visualization
for angle in range(0, 360, 5):
ax.view_init(30, angle)
plt.draw()
plt.pause(0.001)
plt.show()
هذا ليس مجرد مخطط بسيط، بل تصور ثلاثي الأبعاد متحرك يساعدك على رؤية البيانات من زوايا متعددة.
توجيه LLM باستخدام Cursor Rules
اكتشفت أن بإمكاني جعل الذكاء الاصطناعي أكثر فائدة عبر ملف .cursorrules في جذر المشروع. هذا الملف يحتوي تعليمات توجه طريقة توليد الكود.
إذا أردت شرحًا تفصيليًا لهذا الموضوع، فراجع مقالتي الأخرى عن تحسين البرمجة بالذكاء الاصطناعي باستخدام Cursor rules.
مثال على القواعد التي أضفتها:
<cursorrules_code_style>
- Prefer functional programming over OOP
- Use pure functions with clear input/output
- Use strict typing for all variables and functions
</cursorrules_code_style>
<cursorrules_python_specifics>
- Prefer Pydantic over TypedDict for data models
- Use pyproject.toml over requirements.txt
- For complex structures, avoid generic collections
</cursorrules_python_specifics>
بعدها بدأ الذكاء الاصطناعي يولد كودًا أكثر التزامًا بأسلوبي:
# %%
# Define a Pydantic model for better type safety
from pydantic import BaseModel
from typing import List, Optional
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
species: int
species_name: Optional[str] = None
# Function to convert DataFrame rows to Pydantic models
def convert_to_models(df: pd.DataFrame) -> List[IrisFeatures]:
species_map = {0: "setosa", 1: "versicolor", 2: "virginica"}
return [
IrisFeatures(
sepal_length=row["sepal length (cm)"],
sepal_width=row["sepal width (cm)"],
petal_length=row["petal length (cm)"],
petal_width=row["petal width (cm)"],
species=row["species"],
species_name=species_map[row["species"]]
)
for _, row in df.iterrows()
]
# Convert a sample for demonstration
iris_models = convert_to_models(df.head())
for model in iris_models:
print(model)
استكشاف بيانات Iris
بعد تجهيز البيئة والمساعد، حان وقت التحليل الفعلي.
نظرة أولى على البيانات
لنبدأ بفحص البنية:
# %%
# Get basic information about the dataset
print("Dataset shape:", df.shape)
print("\nClass distribution:")
print(df['species'].value_counts())
# Create a more readable species column
species_names = {0: 'setosa', 1: 'versicolor', 2: 'virginica'}
df['species_name'] = df['species'].map(species_names)
# Display descriptive statistics
print("\nDescriptive statistics:")
print(df.describe())
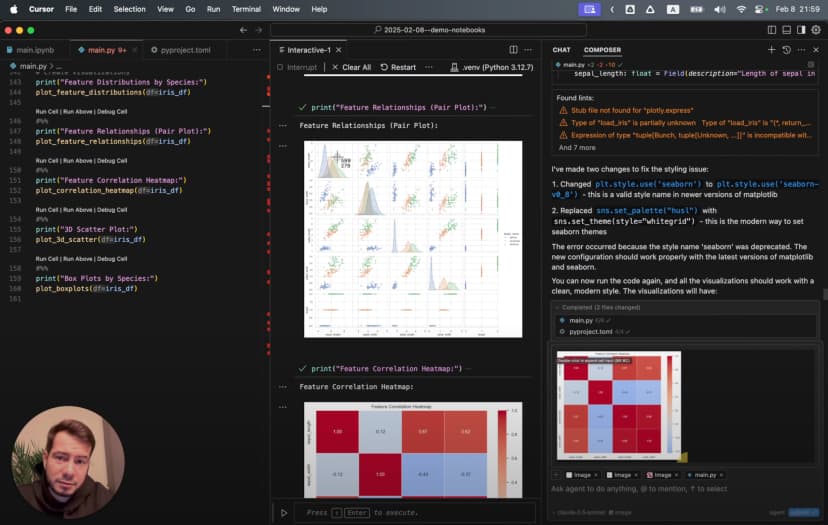
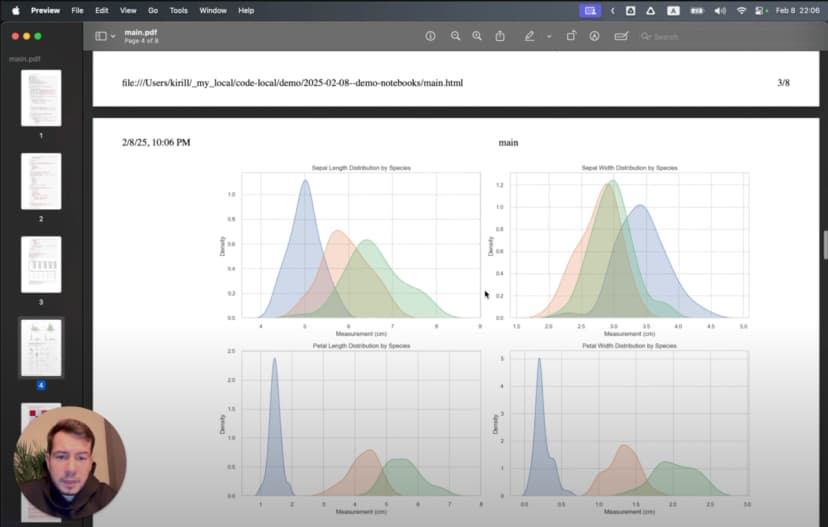
هنا نرى أن لدينا 150 عينة و4 خصائص رئيسية. بعد ذلك يمكننا تصور كل خاصية حسب النوع:
# %%
# Create boxplots for each feature by species
plt.figure(figsize=(12, 10))
for i, feature in enumerate(iris.feature_names):
plt.subplot(2, 2, i+1)
sns.boxplot(x='species_name', y=feature, data=df)
plt.title(f'Distribution of {feature} by Species')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
تظهر هنا أنماط واضحة: Setosa منفصلة بوضوح في بعض الخصائص، وVirginica تمتلك أكبر بتلات.
كشف الأنماط المخفية
ولفهم العلاقات بين الخصائص:
# %%
# Create a pairplot to visualize relationships between features
sns.pairplot(df, hue='species_name', height=2.5)
plt.suptitle('Iris Dataset Pairwise Relationships', y=1.02)
plt.show()
يُظهر هذا الرسم بسرعة أن:
- Setosa منفصلة بوضوح عندما تدخل قياسات البتلات
- Versicolor وVirginica بينهما بعض التداخل
- طول البتلة وعرضها هما أفضل خصيصتين للفصل بين الأنواع
وللتوسع أكثر، راجع دليل scikit-learn.
معالجة مشكلات التكامل والاعتماديات
كما في أي رحلة، ظهرت عقبات. أثناء العمل على تصورات أكثر تعقيدًا واجهت خطأ Seaborn التالي:
ImportError: Seaborn not valid package style
ولتشخيص المشكلة أضفت خلية تفحص الإصدارات:
# %%
# Check installed package versions
import pkg_resources
print("Installed packages:")
for package in ['numpy', 'pandas', 'matplotlib', 'seaborn', 'scikit-learn']:
try:
version = pkg_resources.get_distribution(package).version
print(f"{package}: {version}")
except pkg_resources.DistributionNotFound:
print(f"{package}: Not installed")
اتضح أن إصدار Seaborn غير متوافق مع NumPy. والحل كان عبر terminal المنبثق في Cursor:
- اضغط على أيقونة terminal
- اختر “Pop out terminal”
- نفّذ:
pip install seaborn --upgrade
هذه واحدة من النقاط التي يتفوق فيها Cursor IDE: أصلح الخطأ من دون مغادرة البيئة نفسها.
إنشاء تصورات تكشف فعلاً عن الأنماط
بعد أن أصبح كل شيء يعمل بسلاسة، أردت رسومًا تساعدني على رؤية الأنماط بوضوح.
من رسوم بسيطة إلى تصورات ثلاثية الأبعاد
بدأت بمخطط scatter بسيط لقياسات البتلات:
# %%
# Create a scatter plot of petal dimensions
plt.figure(figsize=(10, 6))
for species_id, species_name in enumerate(iris.target_names):
species_data = df[df['species'] == species_id]
plt.scatter(
species_data['petal length (cm)'],
species_data['petal width (cm)'],
label=species_name,
alpha=0.7,
s=70
)
plt.title('Petal Dimensions by Species')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
ثم أنشأت خريطة حرارية للارتباطات:
# %%
# Calculate correlation matrix
correlation_matrix = df.drop(columns=['species_name']).corr()
# Create a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation_matrix,
annot=True,
cmap='coolwarm',
linewidths=0.5,
vmin=-1,
vmax=1
)
plt.title('Correlation Matrix of Iris Features')
plt.show()
أظهرت الخريطة الحرارية ارتباطًا قويًا جدًا، 0.96، بين طول البتلة وعرضها.
لكن التصور الأبرز ظل الرسم الثلاثي الأبعاد المتحرك، لأنه يكشف زوايا تصبح فيها الأنواع الثلاثة متميزة بوضوح شديد.
مشاركة النتائج: من التحليل إلى العرض
بعد الوصول إلى هذه الاستنتاجات، احتجت إلى مشاركتها مع زملاء لا يملكون Python أو Jupyter. هنا تصبح إمكانيات التصدير مهمة جدًا.
إنشاء تقارير احترافية
لإنتاج تقرير قابل للمشاركة:
- تأكدت من تنفيذ كل الخلايا
- أضفت خلايا markdown لشرح المنهجية والنتائج
- استخدمت خيار “Export as HTML”
- فتحت ملف HTML في المتصفح ثم حفظته PDF
كما أنني أضبط أحيانًا حجم الصورة وجودتها بهذا الشكل:
plt.figure(figsize=(10, 6), dpi=300)
أما التصورات ثلاثية الأبعاد، فأختار أفضل زاوية قبل التصدير لأن الـ PDF سيحتفظ بصورة ثابتة فقط.
كيف تغير سير العمل بالكامل
عندما أنظر للخلف، أجد أن التغيير كان كبيرًا. ما كان يتطلب ثلاث أدوات وانتقالًا مستمرًا بينها، أصبح الآن ممكنًا داخل بيئة واحدة:
- Explore: أستخدم AI لتحميل البيانات وإنشاء تصورات أولية
- Discover: أستفيد من الخلايا التفاعلية لتحسين التحليل
- Document: أوثق النتائج بجانب الشيفرة مباشرة
- Share: أصدّر التحليل كاملًا كتقرير احترافي
الجمع بين تفاعلية Jupyter وقوة التحرير في Cursor IDE ومساعدة AI أزال الكثير من الاحتكاك الذي كان يقطع تركيزي.
وهناك فائدة إضافية مهمة: لأنني أستخدم ملفات نصية عادية بدل .ipynb، أصبح تحليلي كله يدخل إلى git بشكل أنظف وأسهل.
مقارنة: Jupyter التقليدي مقابل Cursor IDE المعزز بـ LLM
الجدول التالي يلخص الفروقات الأساسية:
| Feature | Traditional Jupyter Notebooks | Cursor IDE with Plain Text Jupyter |
|---|---|---|
| File Format | Complex JSON (.ipynb) | Plain text Python (.py) |
| Version Control | Difficult (large diffs, merge conflicts) | Excellent (standard git workflow) |
| IDE Features | Limited code navigation and refactoring | Full IDE capabilities (search, replace, navigation) |
| AI Assistance | Limited | Powerful LLM integration with context awareness |
| Cell Execution | Browser-based interface | Native IDE environment |
| Context Switching | Required for advanced editing | Everything in one environment |
| Performance | Can be slow with large notebooks | Native editor performance |
| Debugging | Limited debugging capabilities | Full IDE debugging tools |
| Export Options | HTML, PDF, various formats | Same capabilities through extension |
| Collaboration | Challenging with version control | Standard code collaboration workflows |
| Dependencies | Managed in separate environment files | Integrated environment management |
| Hidden State Issues | Common problem with out-of-order execution | Reduced by linear execution encouragement |
| Markdown Support | Native | Through cell markers with same capabilities |
| Typechecking | None | Full IDE static analysis support |
| Extension Ecosystem | Jupyter extensions | IDE extensions + Jupyter extensions |
لهذا أرى أن هذا النهج أقوى بكثير للعمل الجاد في تحليل البيانات.
إذا أردت فهمًا أوسع لبنية Jupyter وقدراته، فراجع Project Jupyter Documentation.
الفيديو الكامل
إذا كنت تفضل التعلم المرئي، فقد سجلت شرحًا شاملًا يغطي كل ما في هذه المقالة:

في الفيديو سترى خطوة بخطوة كيف تجهز Jupyter داخل Cursor IDE، وكيف تستخدم التكامل مع AI، وكيف تبني التصورات، وكيف تصدّر النتيجة وأنت ما زلت داخل بيئة واحدة.