[zh]
[Article]

为什么我用一种类 SQL 的 DSL 取代了 17 个智能体工具,让 LLM 的查询、写入和过滤都更简单
我在 Flashcards Open Source App 里把 17 个分散的智能体工具收敛成一个类 SQL 的 DSL 接口,让内部和外部 LLM 更容易学会查询、更新、删除、过滤和汇总,也让这套面向智能体的 API 更一致、更容易上手,同时显著减少提示词负担和工具选择成本。
关于人工智能、技术和商业战略的专业文章
我在 Flashcards Open Source App 里把 17 个分散的智能体工具收敛成一个类 SQL 的 DSL 接口,让内部和外部 LLM 更容易学会查询、更新、删除、过滤和汇总,也让这套面向智能体的 API 更一致、更容易上手,同时显著减少提示词负担和工具选择成本。

这篇文章写我如何用 AI 整理银行流水、自动分类记账、核对多个账户余额,并维护一份滚动 12 个月预算,用来判断现金流是否稳健、多币种收支怎样归类,以及旅行、家具或其他大额支出到底该不该现在发生,也让我能更早发现预算里的危险月份并调整计划,还更方便比较不同账户和月份之间的变化趋势。
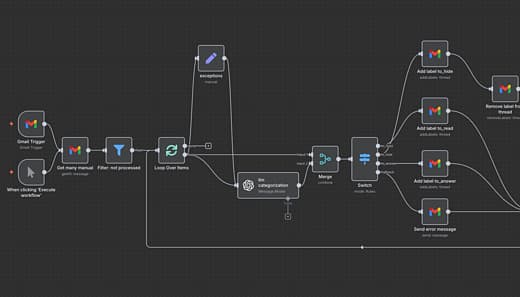
我用 n8n 和 GPT-5-nano 搭了一个自动分类个人邮件的工作流,让 AI 把每封邮件分到“直接归档”“稍后阅读”和“需要回复”三类。它已经稳定跑了三个月,成本很低,逻辑也足够简单,确实帮我省下了每天手动整理收件箱和判断优先级的时间,而且后续几乎不需要额外人工维护和持续盯盘。
这套经过长期实践的 Notion 任务系统,把人生方向、季度目标、项目计划、日常任务和零散想法都放进同一个数据库,再通过父子层级、收件箱清理和 S0-S4 排序,把每天该做的事从杂乱待办中筛出来,减少上下文切换,也避免任务越积越多时的失控感,也更容易把长期目标和当天行动真正接起来。
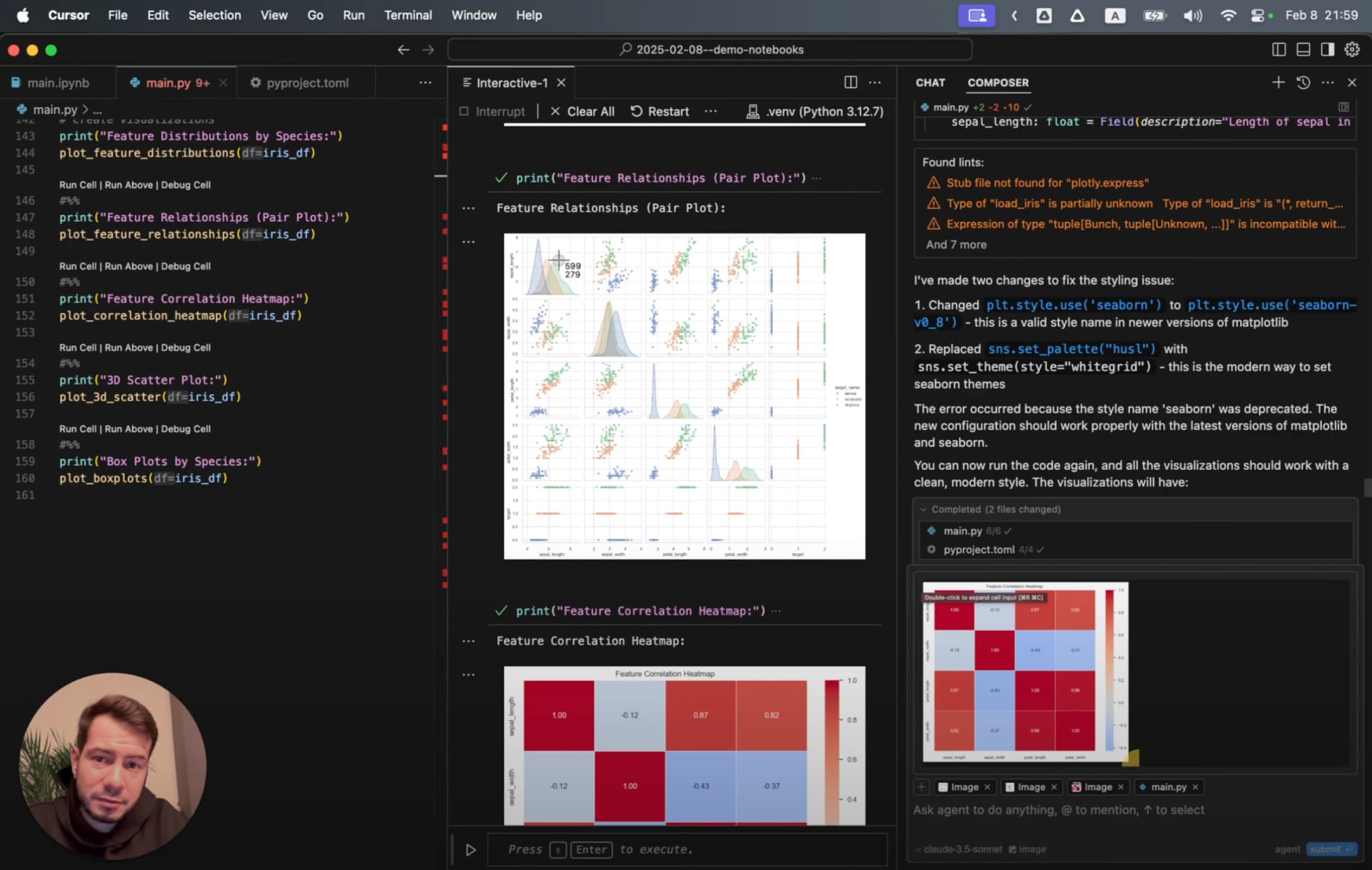
一步步介绍如何在 Cursor IDE 中把 Jupyter Notebook 与 LLM 纳入同一工作流,用纯文本笔记本完成数据分析、可视化、文档整理与报告导出,并让 AI 在保留上下文的同时协助编写、调试和改写代码,减少工具切换带来的摩擦,避免在编辑器、笔记本、图表和文档之间反复切换。

这篇文章梳理一种反复出现的创作冲动:喜剧演员拆解喜剧,管理者建立不依赖自己的系统,工程师用 AI 自动化自己的工作。作者借这些例子讨论,为什么人会主动削弱自身的重要性,以及这种自我拆解为何反而可能让作品、团队和职业判断更有价值。它关注的不是口号式反技术,而是熟悉这门手艺的人,如何亲手把自己变得没那么必要。
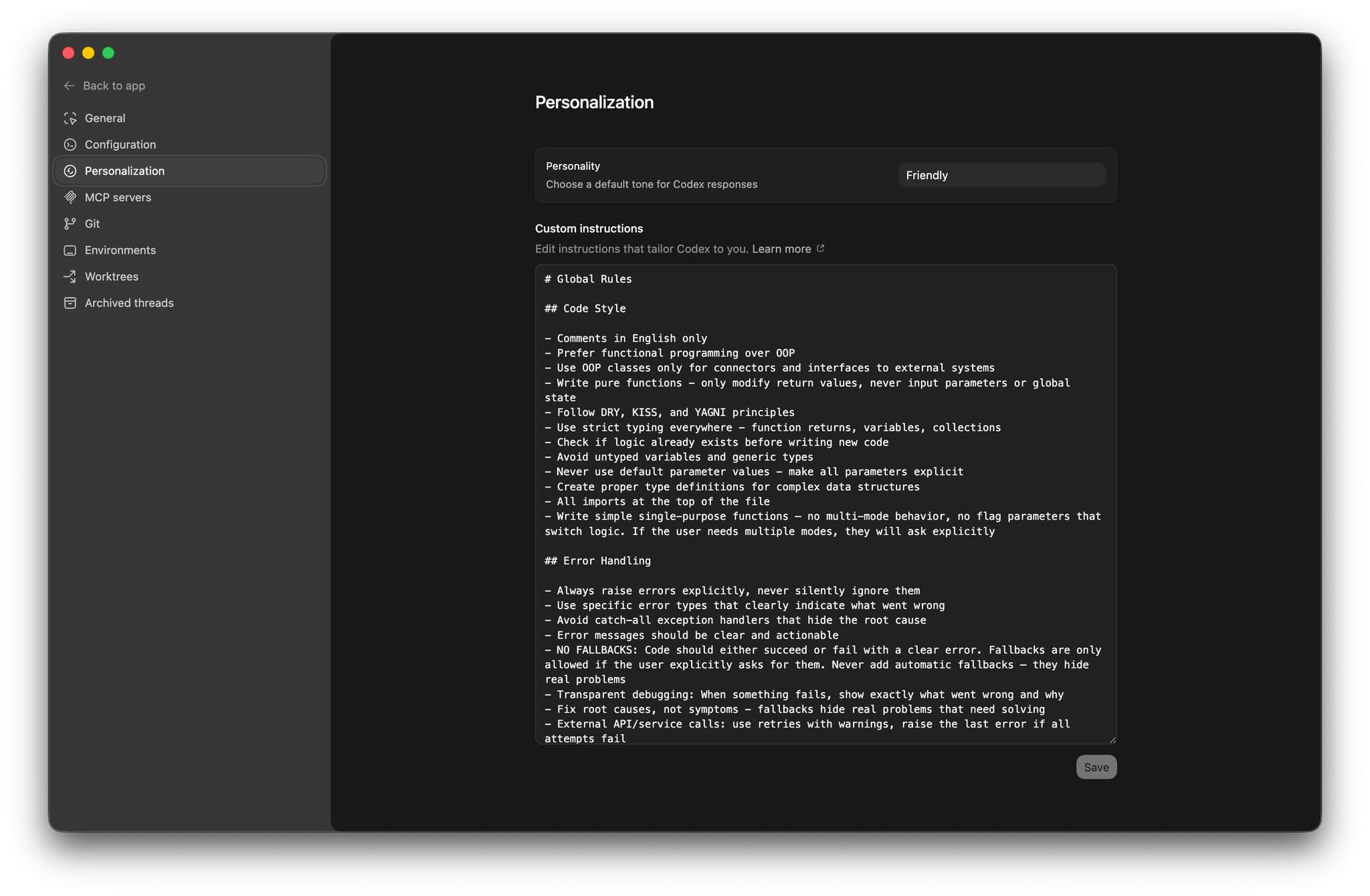
这篇文章介绍我如何使用 Codex 自定义指令、个人与仓库级 AGENTS.md,以及 Mac 应用,让不同代码仓库从一开始就共享同一套编码规则、显式报错要求、最小改动原则和文档习惯,不必在每个新任务里反复重新说明,也让 Codex 进入任何仓库前就先带着这些长期有效的开发模式。
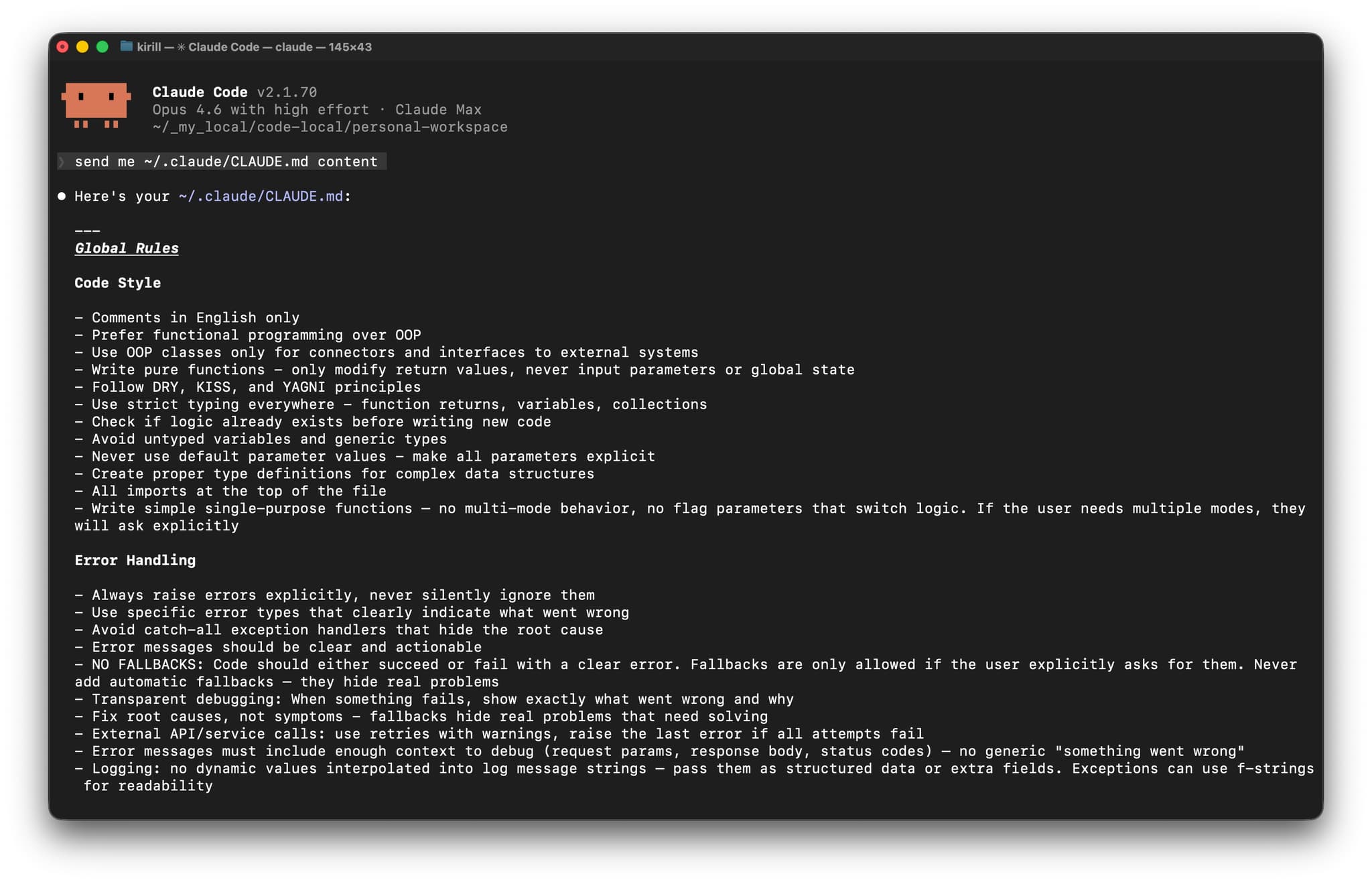
我把默认规则写进 `~/.claude/CLAUDE.md`,把个人偏好和项目规则分开管理,让 Claude Code 在不同仓库里都沿用同一套编码习惯、改动边界和协作方式,不必在每次新对话里重复解释严格类型、不要乱加兜底逻辑、尽量保持小改动,以及别因为一时兴起就重写半个文件这些基础要求。

分享我在 Cursor IDE 中长期使用的一套全局 AI 规则,以及它如何与仓库级规则和按上下文触发的规则配合,帮助 AI 在代码风格、类型约束、错误处理、依赖管理和开发流程上持续输出更稳定、更一致的结果,减少返工,也让个人项目和团队协作里的 AI 输出保持同一水准,并减少沟通成本。

这篇文章总结了我在个人品牌建设和业务运营中长期使用的一套内容分发框架:先根据内容形式选择首发平台,再决定是独家、跨平台同步还是延后发布,然后利用初始流量完成第一轮扩散,并把表现稳定的内容持续沉淀为长期资产,让每篇内容都更容易兼顾短期传播、跨平台复用、搜索流量和长期沉淀,并提高长期回报率。