De la frustración al flow: mi recorrido con Jupyter Notebooks, LLM y Cursor IDE
El problema: los LLM y Jupyter Notebooks no se llevan especialmente bien
Eran las 2 de la madrugada cuando por fin admití la derrota. Mi análisis de secuenciación genómica estaba atascado porque el asistente LLM dentro de Cursor IDE no lograba interpretar bien la compleja estructura JSON de mi notebook de Jupyter. Cada vez que intentaba pedir ayuda con el código de visualización, el resultado era un JSON roto que ni siquiera cargaba. Intenté mandar solo fragmentos, pero eso eliminaba todo el contexto de los pasos de preprocesado. Mientras tanto, tenía tres ventanas abiertas: Jupyter en el navegador, VSCode para el “código serio” y otro editor para la documentación. La combinación de limitaciones del LLM con el formato de Jupyter y el cambio constante de contexto hacía casi imposible trabajar con datos complejos. Incluso con un dataset simple como Iris, esa incompatibilidad básica estaba destruyendo mi productividad.
¿Te suena? Los flujos de trabajo de ciencia de datos suelen ser especialmente brutales con el cambio de contexto. Saltas constantemente entre:
- Editores de código para la parte “seria”
- Jupyter notebooks para explorar
- Herramientas de documentación para compartir hallazgos
- Software de visualización para generar gráficas
- ChatGPT y Claude abiertos en el navegador
Cada cambio consume energía mental y añade fricción. Pero, ¿y si hubiera una forma mejor?
¿Prefieres video? Grabé una demostración paso a paso de este flujo completo. Mira Jupyter Notebooks in Cursor IDE Tutorial with AI-Powered Data Analysis para verlo en acción.
El descubrimiento: una experiencia unificada de data science con LLM en Cursor IDE
Fue entonces cuando encontré una solución que cambió por completo mi flujo de trabajo: usar notebooks de Jupyter directamente dentro de Cursor IDE, reforzados por IA. Este enfoque combina:
- La ejecución interactiva por celdas de Jupyter
- Las funciones potentes de edición y navegación de un IDE real
- Asistencia de IA que entiende tanto código como conceptos de data science
- Archivos de texto plano que funcionan muy bien con control de versiones
Al final de este artículo verás cómo construí un entorno integrado que me permite:
- Analizar datasets y generar visualizaciones con muy poco código manual
- Crear visualizaciones 3D que revelan patrones ocultos
- Documentar hallazgos junto al código
- Exportar informes profesionales con un solo comando
- Hacer todo esto sin ir saltando entre herramientas
Si quieres terminar con la locura del cambio de contexto, sigamos.
Preparar el entorno de Jupyter en Cursor IDE
Toda expedición necesita preparación. Para usar Jupyter en Cursor IDE hay que instalar las herramientas correctas y dejar el entorno listo.
Instalar la extensión de Jupyter
La magia empieza con la extensión Jupyter para Cursor IDE:
- Abre Cursor IDE y crea una carpeta de proyecto
- Ve a Extensions en la barra lateral
- Busca “Jupyter” y encuentra la extensión oficial
- Haz clic en “Install”
Esta extensión es el puente entre los notebooks tradicionales y el IDE. Habilita algo muy útil: usar marcadores especiales en archivos Python normales para crear celdas ejecutables. Ya no necesitas depender de .ipynb con JSON complejo; puedes trabajar con Python en texto plano.
Si quieres profundizar en Jupyter Notebook, consulta la documentación oficial.
Preparar el entorno de Python
Con la extensión instalada, toca crear un entorno limpio:
python -m venv .venv
Después crea un pyproject.toml para gestionar dependencias:
[build-system]
requires = ["setuptools>=42.0", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "jupyter-cursor-project"
version = "0.1.0"
description = "Data analysis with Jupyter in Cursor IDE"
[tool.poetry.dependencies]
python = "^3.9"
jupyter = "^1.0.0"
pandas = "^2.1.0"
numpy = "^1.25.0"
matplotlib = "^3.8.0"
seaborn = "^0.13.0"
scikit-learn = "^1.2.0"
Instala esas dependencias en el entorno virtual:
pip install -e .
Aprendí por las malas que los conflictos de versiones provocan errores muy raros. Si la IA te sugiere código que importa una librería, comprueba antes que realmente esté instalada.
Crear tu primer notebook: el poder del texto plano
Los notebooks tradicionales usan .ipynb, una estructura JSON compleja difícil de editar a mano y todavía más difícil de modificar con IA sin romper el archivo. En su lugar, podemos usar un enfoque en texto plano que conserva lo mejor de ambos mundos.
El problema con los notebooks originales
Así se ve un .ipynb tradicional en un editor de texto:
{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# My Notebook Title\n",
"This is a markdown cell with text."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": ["Hello, world!"]
}
],
"source": [
"print(\"Hello, world!\")"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 4
}
Para un LLM, esta estructura es especialmente incómoda porque:
- El JSON incluye símbolos y anidamientos que no son el contenido real
- Cada celda guarda su contenido como arrays de strings con escapes
- El código y sus salidas viven en partes distintas
- Un cambio pequeño exige respetar todo el esquema del archivo
- Pequeñas ediciones generan diffs grandes y poco precisos
Por eso, cuando un LLM intenta editar este formato, es muy fácil que rompa el notebook.
La magia de los marcadores de celda
Crea un archivo main.py y añade la primera celda:
# %%
# Import necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Display settings for better visualization
pd.set_option('display.max_columns', None)
plt.style.use('ggplot')
print("Environment ready for data analysis!")
Ese # %% le dice a la extensión de Jupyter que ahí empieza una celda ejecutable. En cuanto lo pones, aparecen botones de ejecución al lado. Puedes correr solo esa parte y ver el resultado directamente dentro del editor.
Ahora añade una celda markdown:
# %% [markdown]
"""
# Iris Dataset Analysis
This notebook explores the famous Iris flower dataset to understand:
- The relationships between different flower measurements
- How these measurements can distinguish between species
- Which features provide the best separation between species
Each flower in the dataset belongs to one of three species:
1. Setosa
2. Versicolor
3. Virginica
"""
Esa combinación es potentísima: código ejecutable y documentación rica en el mismo archivo de texto. Sin formatos especiales, sin limitaciones del navegador y con muy buena integración con git.
A medida que construyamos el notebook, seguiremos esta estructura:
- Usar
# %%para celdas de código - Usar
# %% [markdown]con triple comillas para documentación - Mantener un flujo lógico desde carga de datos hasta visualización
- Documentar el proceso y los hallazgos en el camino
Soltar al asistente LLM: tu compañero de data science
Lo que vuelve realmente transformador este flujo es su integración con Cursor Composer. No es solo autocompletado: se comporta como un compañero colaborativo.
Agent Mode: un asistente de ciencia de datos impulsado por LLM
En Cursor IDE, haz clic en “Composer” y elige “Agent Mode”. Eso activa un asistente más sofisticado que:
- Mantiene contexto entre interacciones
- Entiende tu dataset y tus objetivos de análisis
- Genera celdas completas con sintaxis correcta de Jupyter
- Crea visualizaciones adaptadas a tus datos
Podemos pedirle que importe un dataset:
Please import the Iris dataset in this notebook format
La IA genera una celda completa y ejecutable:
# %%
# Import necessary libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# Load the Iris dataset
iris = load_iris()
# Convert to pandas DataFrame
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['species'] = iris.target
# Display the first few rows
print(df.head())
Una sola instrucción, y ya tenemos una celda perfectamente formateada que carga los datos.
Lo mejor llega cuando le pides una visualización:
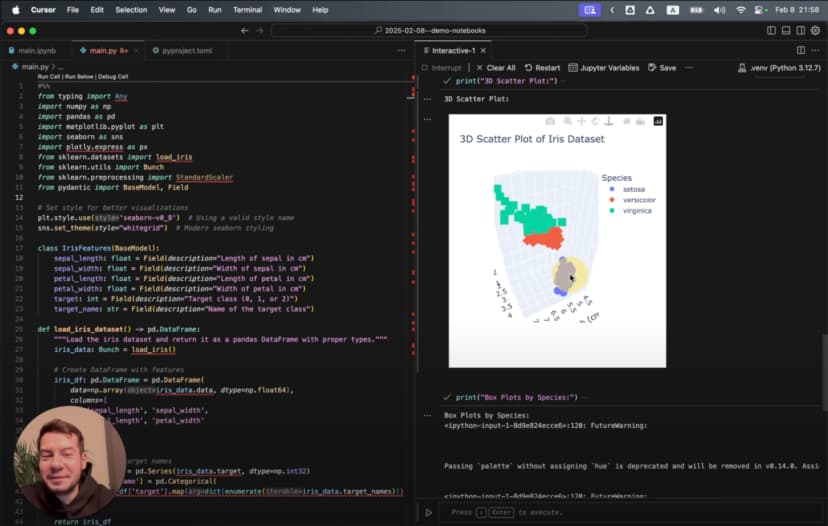
Generate a 3D scatter plot for the iris dataset showing the three species in different colors
La IA produce una visualización 3D bastante sofisticada:
# %%
# Create 3D scatter plot
from mpl_toolkits.mplot3d import Axes3D
# Create figure and 3D axis
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# Get the three species
species_names = iris.target_names
colors = ['blue', 'red', 'green']
# Plot each species with a different color
for species_id, species_name in enumerate(species_names):
# Filter data for this species
species_data = df[df['species'] == species_id]
# Plot this species
ax.scatter(
species_data['sepal length (cm)'],
species_data['sepal width (cm)'],
species_data['petal length (cm)'],
c=colors[species_id],
label=species_name,
s=60,
alpha=0.8
)
# Set labels and title
ax.set_xlabel('Sepal Length (cm)')
ax.set_ylabel('Sepal Width (cm)')
ax.set_zlabel('Petal Length (cm)')
ax.set_title('3D Scatter Plot of Iris Dataset')
ax.legend()
# Add rotation for better visualization
for angle in range(0, 360, 5):
ax.view_init(30, angle)
plt.draw()
plt.pause(0.001)
plt.show()
No es solo una gráfica cualquiera: es una visualización animada que rota para mostrar los datos desde distintos ángulos.
Guiar al LLM con Cursor Rules
Descubrí que podía hacer a la IA todavía más útil si añadía un archivo .cursorrules en la raíz del proyecto. Ese archivo contiene instrucciones personalizadas que guían la generación de código.
Si quieres profundizar en esto, tengo otra guía sobre cómo optimizar la programación con IA usando Cursor rules.
Por ejemplo, añadí reglas como estas:
<cursorrules_code_style>
- Prefer functional programming over OOP
- Use pure functions with clear input/output
- Use strict typing for all variables and functions
</cursorrules_code_style>
<cursorrules_python_specifics>
- Prefer Pydantic over TypedDict for data models
- Use pyproject.toml over requirements.txt
- For complex structures, avoid generic collections
</cursorrules_python_specifics>
Con estas reglas, la IA empezó a generar código más alineado con mis preferencias:
# %%
# Define a Pydantic model for better type safety
from pydantic import BaseModel
from typing import List, Optional
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
species: int
species_name: Optional[str] = None
# Function to convert DataFrame rows to Pydantic models
def convert_to_models(df: pd.DataFrame) -> List[IrisFeatures]:
species_map = {0: "setosa", 1: "versicolor", 2: "virginica"}
return [
IrisFeatures(
sepal_length=row["sepal length (cm)"],
sepal_width=row["sepal width (cm)"],
petal_length=row["petal length (cm)"],
petal_width=row["petal width (cm)"],
species=row["species"],
species_name=species_map[row["species"]]
)
for _, row in df.iterrows()
]
# Convert a sample for demonstration
iris_models = convert_to_models(df.head())
for model in iris_models:
print(model)
La IA siguió mis reglas bastante bien y terminó generando código tipado, funcional y más consistente.
Explorar el dataset Iris con Python
Con el entorno listo y el asistente preparado, toca empezar la exploración del clásico dataset Iris.
Primera mirada a los datos
Ya tenemos el dataset cargado, así que primero exploramos su estructura:
# %%
# Get basic information about the dataset
print("Dataset shape:", df.shape)
print("\nClass distribution:")
print(df['species'].value_counts())
# Create a more readable species column
species_names = {0: 'setosa', 1: 'versicolor', 2: 'virginica'}
df['species_name'] = df['species'].map(species_names)
# Display descriptive statistics
print("\nDescriptive statistics:")
print(df.describe())
Esto nos muestra 150 muestras en total, 50 de cada especie, y 4 variables principales. Ahora podemos visualizar cómo cambia cada característica según la especie:
# %%
# Create boxplots for each feature by species
plt.figure(figsize=(12, 10))
for i, feature in enumerate(iris.feature_names):
plt.subplot(2, 2, i+1)
sns.boxplot(x='species_name', y=feature, data=df)
plt.title(f'Distribution of {feature} by Species')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
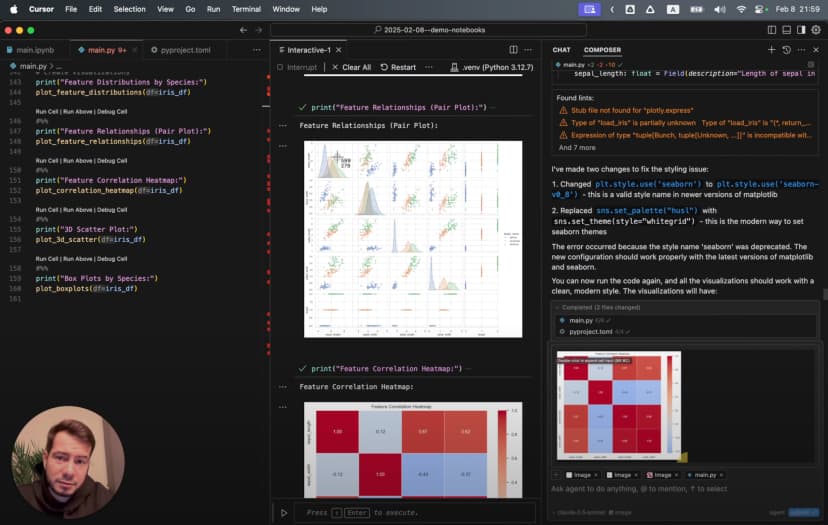
Los boxplots revelan patrones interesantes: Setosa tiene sépalos relativamente anchos y pétalos pequeños; Virginica tiene los pétalos más grandes.
Descubrir patrones ocultos
Para entender mejor las relaciones entre variables:
# %%
# Create a pairplot to visualize relationships between features
sns.pairplot(df, hue='species_name', height=2.5)
plt.suptitle('Iris Dataset Pairwise Relationships', y=1.02)
plt.show()
Ese pairplot deja ver rápidamente que:
- Setosa aparece completamente separada cuando intervienen medidas de pétalos
- Versicolor y Virginica se solapan un poco, pero siguen siendo distinguibles
- La longitud y anchura del pétalo son las variables que mejor separan las tres especies
Si quieres ampliar este tipo de análisis, el User Guide de scikit-learn es una muy buena referencia.
Resolver problemas de integración: dependencias y errores
Como en toda aventura, aparecieron obstáculos. Cuando empecé a trabajar con visualizaciones más complejas me encontré con este error de Seaborn:
ImportError: Seaborn not valid package style
Es un problema bastante común en entornos de ciencia de datos: incompatibilidades de versiones entre paquetes. Para diagnosticarlo añadí una celda para revisar versiones instaladas:
# %%
# Check installed package versions
import pkg_resources
print("Installed packages:")
for package in ['numpy', 'pandas', 'matplotlib', 'seaborn', 'scikit-learn']:
try:
version = pkg_resources.get_distribution(package).version
print(f"{package}: {version}")
except pkg_resources.DistributionNotFound:
print(f"{package}: Not installed")
Descubrí que mi versión de Seaborn no era compatible con la de NumPy. La solución fue usar la terminal emergente de Cursor:
- Haz clic en el icono de terminal del panel inferior
- Selecciona “Pop out terminal”
- Ejecuta:
pip install seaborn --upgrade
Aquí es donde Cursor IDE brilla: pude solucionar la dependencia sin salir de la herramienta ni perder el contexto del análisis.
Crear visualizaciones que de verdad revelan patrones
Una vez resuelto el entorno, quise crear gráficos que no solo se vieran bien, sino que ayudaran a entender el dataset.
De gráficos simples a visualizaciones 3D
Empecé con un scatter plot sencillo centrado en las dimensiones del pétalo:
# %%
# Create a scatter plot of petal dimensions
plt.figure(figsize=(10, 6))
for species_id, species_name in enumerate(iris.target_names):
species_data = df[df['species'] == species_id]
plt.scatter(
species_data['petal length (cm)'],
species_data['petal width (cm)'],
label=species_name,
alpha=0.7,
s=70
)
plt.title('Petal Dimensions by Species')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
Ese gráfico muestra enseguida cómo Setosa forma un clúster compacto.
Después añadí un mapa de calor de correlaciones:
# %%
# Calculate correlation matrix
correlation_matrix = df.drop(columns=['species_name']).corr()
# Create a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(
correlation_matrix,
annot=True,
cmap='coolwarm',
linewidths=0.5,
vmin=-1,
vmax=1
)
plt.title('Correlation Matrix of Iris Features')
plt.show()
El heatmap mostró una correlación muy fuerte, 0.96, entre la longitud y la anchura del pétalo.
Pero la visualización más impactante seguía siendo el scatter 3D animado. A medida que rota, aparecen ángulos donde las tres especies quedan visualmente clarísimas.
Compartir los hallazgos: del análisis a la presentación
Después de obtener estos insights, necesitaba compartirlos con colegas que no tienen Python ni Jupyter instalados. Ahí es donde las opciones de exportación resultan muy valiosas.
Crear informes profesionales
Para generar un informe compartible:
- Me aseguré de que todas las celdas estuvieran ejecutadas
- Añadí celdas markdown para explicar metodología y conclusiones
- Usé la opción “Export as HTML”
- Abrí el HTML en el navegador y guardé como PDF
El resultado fue un documento que incluía código, explicaciones y visualizaciones en un formato que cualquiera podía abrir. También cuidé el tamaño de las figuras para presentaciones y PDF:
plt.figure(figsize=(10, 6), dpi=300)
En el caso de las visualizaciones 3D, antes de exportar colocaba la cámara en el ángulo más informativo, ya que en el PDF la animación se convierte en una imagen estática.
La transformación del flujo de trabajo
Mirando atrás, el cambio es claro. Lo que antes requería tres herramientas distintas y un cambio de contexto constante, ahora sucede dentro de un único entorno:
- Explore: uso la IA para cargar datos y crear visualizaciones iniciales
- Discover: aprovecho la ejecución por celdas para refinar el análisis
- Document: escribo mis hallazgos junto al código
- Share: exporto el análisis completo como informe profesional
La combinación de interactividad de Jupyter, edición potente de Cursor IDE y asistencia de IA elimina gran parte de la fricción que antes rompía mi concentración.
Además, hay un beneficio extra: como trabajo con archivos de texto plano en vez de notebooks .ipynb, todo el análisis entra mejor en git. Veo con claridad qué cambió entre versiones y evito muchos conflictos de merge.
Si estás cansado de ir saltando entre herramientas para hacer data science, este enfoque integrado merece la pena.
Comparación: Jupyter tradicional vs Cursor IDE con LLM
Esta tabla resume bien las diferencias:
| Feature | Traditional Jupyter Notebooks | Cursor IDE with Plain Text Jupyter |
|---|---|---|
| File Format | Complex JSON (.ipynb) | Plain text Python (.py) |
| Version Control | Difficult (large diffs, merge conflicts) | Excellent (standard git workflow) |
| IDE Features | Limited code navigation and refactoring | Full IDE capabilities (search, replace, navigation) |
| AI Assistance | Limited | Powerful LLM integration with context awareness |
| Cell Execution | Browser-based interface | Native IDE environment |
| Context Switching | Required for advanced editing | Everything in one environment |
| Performance | Can be slow with large notebooks | Native editor performance |
| Debugging | Limited debugging capabilities | Full IDE debugging tools |
| Export Options | HTML, PDF, various formats | Same capabilities through extension |
| Collaboration | Challenging with version control | Standard code collaboration workflows |
| Dependencies | Managed in separate environment files | Integrated environment management |
| Hidden State Issues | Common problem with out-of-order execution | Reduced by linear execution encouragement |
| Markdown Support | Native | Through cell markers with same capabilities |
| Typechecking | None | Full IDE static analysis support |
| Extension Ecosystem | Jupyter extensions | IDE extensions + Jupyter extensions |
Por eso me parece un enfoque mucho más sólido para trabajo serio de análisis de datos.
Si quieres más contexto sobre la arquitectura completa de Jupyter, consulta la Project Jupyter Documentation.
Video tutorial
Si prefieres aprender visualmente, he creado un tutorial completo que recorre todos los conceptos del artículo:

En el video muestro cada paso de la configuración y el uso de Jupyter notebooks en Cursor IDE, cómo funciona la integración con IA, cómo crear visualizaciones y cómo exportar resultados sin salir de un entorno unificado.