Cursor IDE AI编码规则深度优化:提升开发效率的实战指南
Cursor IDE通过三级规则体系实现智能编码辅助:
- 全局基础规则 - 跨项目通用编码标准
- 仓库级.cursor/index.mdc配置(Rule Type "Always") - 项目专属开发规范(替代传统.cursorrules方案)
- 动态.cursor/rules/*.mdc文件 - 任务导向的智能提示
本文将重点解析我的全局规则配置,这些经过实战检验的设置构成了高效AI协作的基础框架。结合项目级和动态规则,这套系统能在保证代码质量的同时,显著提升日常开发效率。
更倾向于视频教程? 我制作了一个全面的视频演练,详细介绍了整个 cursor 规则系统。观看 Ultimate Cursor AI IDE Rules Guide: All 5 Levels and .cursorrules (2025) 来查看这些技术的分步实现。

实战指南:如何配置Cursor AI编码规则实现最佳性能
根据我的经验,以下步骤能最大化AI编码效率:
-
导航到设置
Cursor -> 设置 -> Cursor设置 -> AI规则 -
配置全局规则
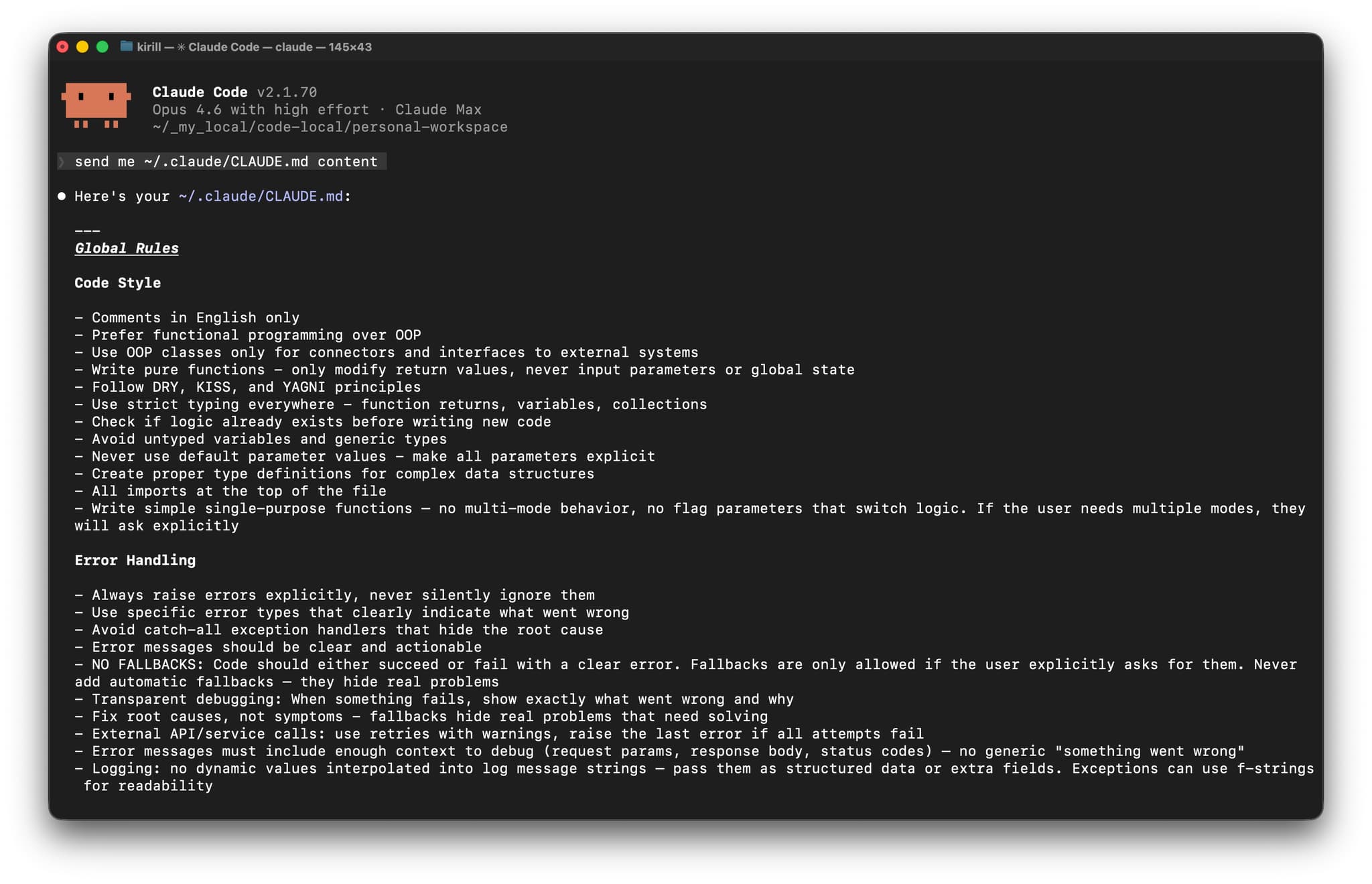
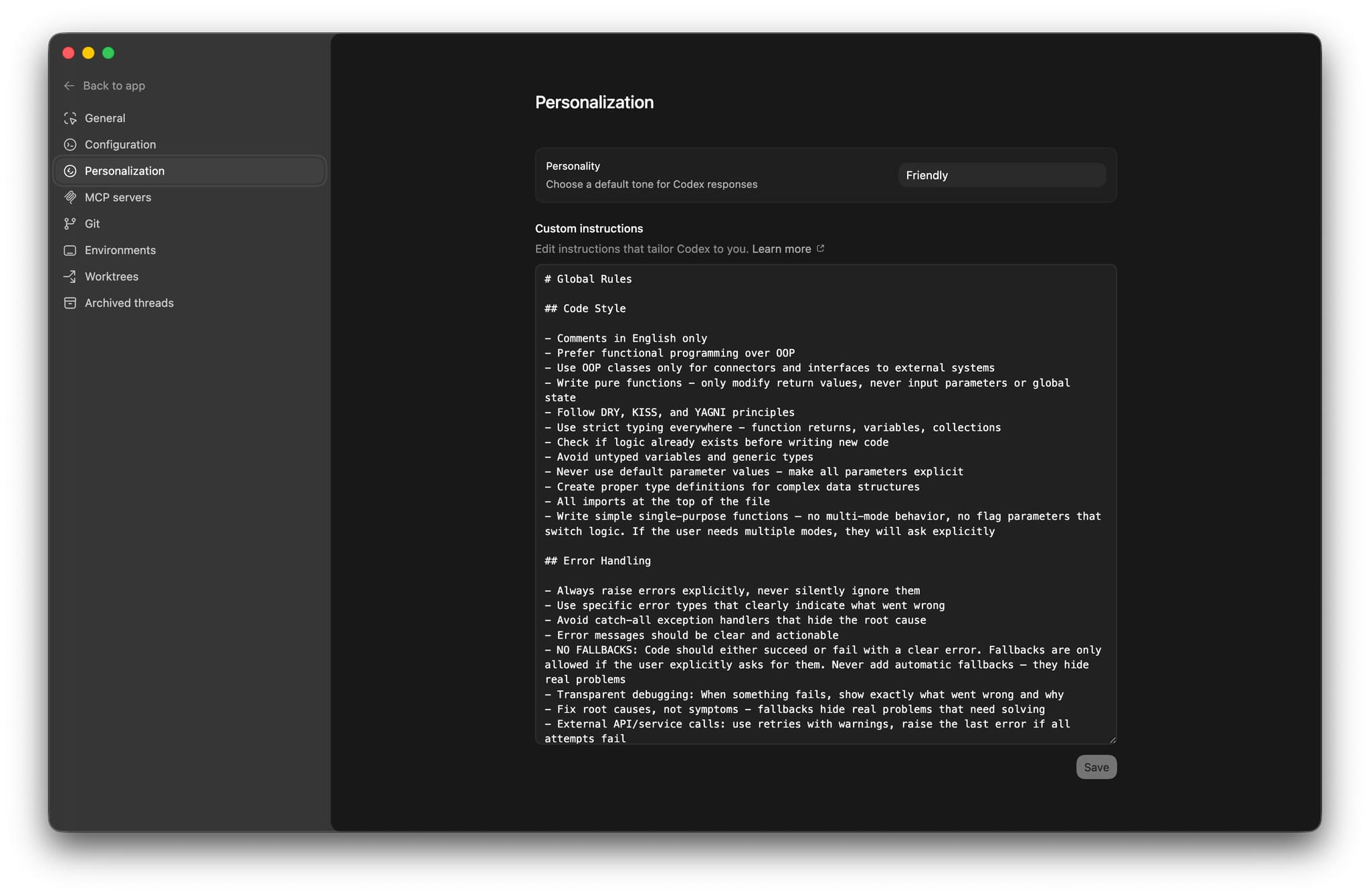
以下是我的基础配置,经过3个月迭代优化:
# Global Rules
## Code Style
- Comments in English only
- Prefer functional programming over OOP
- Use OOP classes only for connectors and interfaces to external systems
- Write pure functions - only modify return values, never input parameters or global state
- Follow DRY, KISS, and YAGNI principles
- Use strict typing everywhere - function returns, variables, collections
- Check if logic already exists before writing new code
- Avoid untyped variables and generic types
- Never use default parameter values - make all parameters explicit
- Create proper type definitions for complex data structures
- All imports at the top of the file
- Write simple single-purpose functions — no multi-mode behavior, no flag parameters that switch logic. If the user needs multiple modes, they will ask explicitly
## Error Handling
- Always raise errors explicitly, never silently ignore them
- Use specific error types that clearly indicate what went wrong
- Avoid catch-all exception handlers that hide the root cause
- Error messages should be clear and actionable
- NO FALLBACKS: Code should either succeed or fail with a clear error. Fallbacks are only allowed if the user explicitly asks for them. Never add automatic fallbacks — they hide real problems
- Transparent debugging: When something fails, show exactly what went wrong and why
- Fix root causes, not symptoms - fallbacks hide real problems that need solving
- External API/service calls: use retries with warnings, raise the last error if all attempts fail
- Error messages must include enough context to debug (request params, response body, status codes) — no generic "something went wrong"
- Logging: no dynamic values interpolated into log message strings — pass them as structured data or extra fields. Exceptions can use f-strings for readability
## Language Specifics
- Prefer structured data models over loose dictionaries (Pydantic, interfaces)
- Avoid generic types like `Any`, `unknown`, or `List[Dict[str, Any]]`
- Use modern package management (pyproject.toml, package.json)
- Leverage language-specific type features (discriminated unions, enums)
## Libraries and Dependencies
- Install in virtual environments, not globally
- Add to project configs, not one-off installs
- When a dependency is installed locally (node_modules, .venv, etc.), read its source code directly even if it's gitignored — this is the best way to understand how a library works
- Update project configuration files when adding dependencies
## Terminal Usage
- Always use non-interactive git diff: `git --no-pager diff` or `git diff | cat`
- Prefer non-interactive commands with flags over interactive ones
## Code Changes
- Matching the existing code style is more important than "correct" or "ideal" style — new code must look like it was written by the same author
- Suggest only minimal changes related to current dialog
- Change as few lines as possible while solving the problem
- Focus only on what user is asking for - no extra improvements
## Documentation
- Code is the primary documentation — use clear naming, types, and docstrings
- Keep documentation in docstrings of the functions/classes they describe, not in separate files
- Separate docs files (in `docs/`) only when a concept cannot be expressed in code — and only one file per topic
- Never duplicate documentation across files — reference other sources instead
- Store knowledge as current state, not as a changelog of modifications

Cursor规则配置演进史
我的规则配置经历了三个阶段的发展:
阶段一:全局设置统一管理
初期将所有规则放入全局设置,简单但效率低下。随着项目增多,配置变得臃肿
阶段二:仓库级规则定制化
将项目特定规则迁移到仓库级配置。初期使用.cursorrules文件(现为传统方式),实现按仓库定制。如今推荐使用.cursor/index.mdc文件(Rule Type "Always")
阶段三:智能情景规则系统
引入.cursor/*.mdc动态规则后:
- 全局设置保持最小化
- 使用
.cursor/index.mdc(Rule Type "Always")定义项目标准(替代传统.cursorrules) - 情景规则处理专项任务
这种分层架构实现了"即时指导"理念,根据当前任务提供精准建议
三级规则体系:智能编码的黄金组合
通过200+小时的实践验证,我发现关键优化点在于:精准控制token消耗。更精简的上下文意味着更强大的代码生成能力。
有关Cursor中规则工作原理的更多信息,请查看Cursor官方文档中关于AI规则的部分。
高效实施三步曲
-
全局规则筑基
从我的配置开始,建立跨项目统一标准。这个基线配置经过3个月迭代,平衡了灵活性和规范性。 -
项目规则定制
当识别出重复模式时,立即迁移到.cursor/index.mdc文件(Rule Type "Always")。比如在Next.js项目中,我们添加了严格的SSR规范。(注:传统.cursorrules文件仍可使用但不再推荐) -
动态规则激活
大型项目必备技巧:当处理API集成时,自动加载REST规范;开发UI组件时激活设计系统规则。
实战案例:生产环境规则配置解析
以下是我在实际项目中应用的规则配置,展示了如何在不同场景下实现高效AI协作:
仓库级规则文件结构
我的.cursor/index.mdc文件(Rule Type "Always")就像为AI定制的README.md,它提供了:
注:以下示例使用传统.cursorrules方法(仍然有效)。新项目建议使用.cursor/index.mdc配置。
- 项目目标 - 明确开发方向
- 架构说明 - 关键设计决策
- 编码模式 - 项目特定约定

实际项目示例
注:这些示例使用传统.cursorrules方法(仍然有效)。新项目建议使用.cursor/index.mdc配置Rule Type "Always"。
-
repo-to-text
这个工具专注于将代码仓库转换为文本格式,其规则包括:- 大型文件处理策略
- 忽略模式配置
- 代码结构保存规范
-
chatgpt-telegram-bot-telegraf
针对Telegram机器人的规则聚焦于:- 架构设计原则
- 消息处理流程
- OpenAI API安全集成
动态规则应用:注意事项与最佳实践
当仓库级规则变得过于庞大时,我将它们拆分为特定上下文的.cursor/*.mdc文件,这些文件仅在相关时激活。

专项任务规则实现示例
我个人网站仓库是很好的例子: website-next-js/.cursor/rules/
在这个仓库中,我创建了多个针对不同任务的规则文件:
- 内容管理工作流程
- 图像优化要求
- SEO最佳实践
- 组件架构模式
- 部署流程
这种方法使AI保持专注,避免在处理特定任务时被不相关的信息干扰。
对话中期规则激活的限制
关键限制:上下文感知的.mdc规则在新对话开始时效果最佳。如果在现有对话中突然需要应用专门规则(如数据库查询指南),AI可能不会自动加载该规则文件。这是因为Cursor已经为对话建立了上下文,不会在对话中期重新评估需要哪些规则。
解决方案
-
明确提示
直接说明需要的规则:"请遵循我们的数据库查询指南完成此任务。" -
启动新对话
对于关键任务,建议启动新对话,Cursor将自动检测并应用所有相关规则。
最佳实践
-
规则命名清晰
使用描述性文件名,如database-queries.mdc或api-integration.mdc -
保持规则简洁
每个文件专注单一主题,避免过度复杂 -
定期审查规则
根据实际使用情况迭代优化规则内容
多级规则配置对比
| 特性 | 全局设置 | 仓库级规则(.cursor/index.mdc "Always") | 情景规则(.cursor/*.mdc) |
|---|---|---|---|
| 适用范围 | 所有项目 | 特定仓库 | 专项任务 |
| 可见性 | 仅本地可见 | 团队共享 | 团队共享 |
| 持久性 | 跨项目保持 | 与仓库绑定 | 与仓库绑定 |
| 激活方式 | 始终启用 | 仓库内始终有效 | 按任务动态激活 |
| 最佳场景 | 通用编码标准 | 项目架构规范 | 领域专业知识 |
| 令牌效率 | 低(始终存在) | 中(项目内始终存在) | 高(仅在需要时加载) |
| 设置位置 | Cursor设置界面 | .cursor/index.mdc文件 | .cursor/rules/*.mdc |
| 可移植性 | 每台设备需手动设置 | 随仓库克隆自动获取 | 随仓库克隆自动获取 |
| 传统支持 | 不适用 | .cursorrules仍可用(传统) | 不适用 |
这种多层次方法使你能够在不同场景下优化令牌使用,同时保持一致的指导。
Cursor规则分步实施指南
全局规则设置步骤
-
打开设置
Cursor -> 设置 -> Cursor设置 -> AI规则 -
配置核心原则
- 添加跨项目通用的编码标准
- 定义基本的错误处理模式
- 设置默认的代码风格偏好
-
保持简洁
- 限制全局规则数量 (建议不超过20条)
- 避免项目特定的细节
- 使用清晰的Markdown格式
-
测试配置
- 通过简单prompt验证规则效果
- 检查生成的代码是否符合预期
- 迭代优化规则表述
高效管理本地Cursor IDE设置
-
多设备同步:虽然设置存储在本地,但可以通过以下方式同步:
- 导出/导入设置文件
- 使用版本控制系统管理配置文件
- 创建共享的配置模板
-
团队协作:
- 建立统一的全局规则模板
- 定期审查和更新规则
- 通过文档共享最佳实践
仓库级规则创建
-
文件位置
在项目中创建.cursor/index.mdc -
配置设置
- 设置Rule Type为"Always"(在Cursor界面或手动指定)
- 项目概述和技术栈
- 架构设计和关键决策
- 代码规范和风格指南
-
最佳实践
- 保持文件长度<100行
- 使用清晰的Markdown标题
- 添加具体示例和代码片段
注:传统.cursorrules文件仍可使用但不再推荐用于新项目。
仓库级Cursor规则模板
# 项目:[项目名称]
## 概述
- 目的:[简短描述]
- 技术栈:[关键技术]
- 架构:[关键模式 - MVC、微服务等]
## 代码模式
- [列出项目特定模式]
## 风格要求
- [项目特定风格指南]
## 错误处理
- [定义异常处理策略]
## 测试规范
- [描述测试方法和覆盖率要求]
智能情景规则配置
-
目录结构
创建.cursor/rules/目录 -
文件命名
- 使用描述性文件名
- 按功能或技术领域分类
- 保持文件名简洁但明确
-
内容组织
- 每个文件专注单一主题
- 使用Markdown标题结构
- 添加具体示例和代码片段
创建规则:手动vs Cursor IDE界面方法
-
手动创建
- 完全控制文件结构和内容
- 适合复杂或定制化规则
- 需要熟悉Markdown语法
-
Cursor界面
- 提供指导性的创建流程
- 自动生成标准文件结构
- 适合快速创建简单规则
React开发的规则文件示例
# React组件指南
## 组件结构
- 使用函数组件
- 定义清晰的TypeScript接口
- 复杂状态管理使用自定义hooks
## 样式设计
- 使用styled components
- 避免内联样式
- 遵循设计系统规范
## 命名约定
- 组件文件:PascalCase.tsx
- Hook文件:use[Name].ts
- 样式文件:[name].styles.ts
## 最佳实践
- 保持组件单一职责
- 使用React.memo优化性能
- 避免不必要的重新渲染
规则配置的量化收益
代码质量提升
- 风格一致性:PR评论减少50%
- 类型安全:类型错误下降35%
- 代码复用:重复率降低42%
- 可维护性:代码审查时间缩短30%
团队协作优化
- 新人上手:培训时间减少60%
- 跨团队沟通:效率提升40%
- 知识共享:规则文件作为统一参考
- 代码审查:聚焦业务逻辑而非风格问题
开发效率增益
- 初始提交:速度加快35%
- 风格修复:提交减少40%
- 认知负荷:降低55%
- 专注度:更多时间用于解决实际问题
高级技巧:专业开发者的规则优化
专项任务规则模板
测试规则 (test-guidelines.mdc)
- 命名模式:统一测试命名规范
- 模拟策略:定义mock数据标准
- 覆盖率:设置最低覆盖率要求
- 断言风格:统一断言方法
API集成规则 (api-standards.mdc)
- 错误处理:定义重试逻辑和超时
- 认证流程:统一认证机制
- 日志记录:规范API调用日志
- 版本控制:定义API版本策略
状态管理规则 (state-patterns.mdc)
- 命名约定:统一action和reducer命名
- 正规化:定义状态结构标准
- 副作用:规范异步操作处理
- 性能优化:定义memoization策略
Token优化策略
- 优先级:将关键规则放在文件开头
- 层次结构:从通用到具体
- 简洁性:避免冗余描述
- 格式化:使用Markdown标题和列表
- 模块化:拆分大型规则文件
常见问题排查指南
规则未生效
- 检查冲突:确保不同级别规则一致
- 验证激活:确认规则文件被正确加载
- 测试响应:通过简单prompt验证效果
性能问题
- 优化上下文:减少不必要的信息
- 拆分规则:将大型文件拆分为专注模块
- 定期审查:移除过时或冗余规则
团队协作
- 统一模板:创建共享的规则模板
- 版本控制:将规则文件纳入Git管理
- 文档化:为复杂规则添加说明
与其他AI工具对比
百度Comate: 项目级配置通过.comate/config.yaml
阿里云Cosy: 使用工作区预设模板
讯飞iFlyCode: 通过code_rules.json管理规范
虽然Cursor有一个特别精心设计的规则系统,但其他AI编码助手也有类似的自定义方法:
- GitHub Copilot 提供
.github/copilot/settings.yml进行项目级配置 - JetBrains AI Assistant 有项目级代码片段和模板
- 带有各种AI扩展的VS Code支持工作区设置和自定义文件
令牌经济学:优化所有工具的AI性能
所有这些方法的共同点是一个基本原则:最小化令牌使用对获取最佳结果至关重要。无论你使用哪种AI编码助手,在不让模型负担过重的情况下提供恰到好处的上下文是成功的关键。
令牌经济学在所有基于LLM的工具中的工作方式相同:
- 你添加到指令中的每个词都会消耗令牌
- 用于指令的令牌会减少用于代码理解的可用上下文
- 极度冗长的指导会导致收益递减
因此,无论你是使用Cursor的三层规则系统还是其他工具的配置选项,始终要力求精确和简洁。将你的指导集中在最重要的特定模式和偏好上,让AI处理其余部分。
技术术语表:帮助初学者理解关键概念
为了帮助初学者更好地理解本文中使用的技术术语,以下是一些核心概念的解释:
| 术语 | 英文原文 | 解释 |
|---|---|---|
| 令牌 | Token | 大语言模型处理文本的基本单位,一个令牌可能是一个单词、部分单词或标点符号。令牌数量直接影响AI响应质量和处理速度。 |
| 上下文窗口 | Context window | 大语言模型在生成回复时能考虑的文本范围,以令牌数量计算。 |
| 规则文件 | Rules file | 在Cursor IDE中定义AI行为准则的配置文件,可以是全局设置、仓库级.cursor/index.mdc文件或情景特定.mdc文件。 |
| 纯函数 | Pure function | 仅依赖于输入参数且不产生副作用的函数,对于相同的输入总是返回相同的输出。 |
| 函数式编程 | Functional programming | 编程范式,强调使用纯函数、避免共享状态和可变数据。 |
| DRY原则 | DRY (Don't Repeat Yourself) | 软件开发原则,提倡减少代码重复,每个知识点在系统中应当有唯一、明确的表示。 |
| KISS原则 | KISS (Keep It Simple, Stupid) | 设计原则,主张简单性应该是首要目标,避免不必要的复杂性。 |
| YAGNI原则 | YAGNI (You Aren't Gonna Need It) | 极限编程原则,建议只有当真正需要某个功能时才实现它。 |
| 类型系统 | Type system | 编程语言中对变量、表达式、函数等分配类型的规则集合,帮助捕获错误并提高代码可读性。 |
| 错误处理 | Error handling | 程序中检测、报告和处理异常情况的方法。 |
| 副作用 | Side effect | 函数调用中除了返回值外对程序状态的任何更改,如修改全局变量或进行I/O操作。 |
| 存储库/仓库 | Repository | 存储代码和其相关资源的地方,通常使用版本控制系统如Git管理。 |
| PR (拉取请求) | Pull Request | 开发者提议将其代码更改合并到项目主分支的请求。 |
| 命名参数 | Named parameters | 在函数调用中明确指定参数名称,提高代码可读性和降低出错可能性。 |
| 强类型 | Strongly typed | 编程语言特性,要求明确指定变量类型,限制不同类型间的自动转换。 |
| .cursorrules | .cursorrules | Cursor IDE中用于配置AI助手行为的传统文件,存放在代码仓库根目录。现已被.cursor/index.mdc取代,但仍然兼容。 |
| .cursor/rules/*.mdc | .cursor/rules/*.mdc | Cursor IDE中用于特定任务或上下文的动态规则文件,只有在相关任务时才会激活。 |
这些概念对于理解如何有效配置和使用Cursor IDE的AI功能至关重要。随着你对这些概念的熟悉,你将能够更有效地创建和管理适合你开发工作流程的AI规则。
真正的优势不在于哪个工具提供最多的自定义选项,而在于你如何周到地使用可用选项来传达你的期望,而不浪费令牌在不必要的冗长表述上。
视频教程:观看完整的 Cursor IDE 规则实施
如果你更喜欢视觉学习,我制作了一个全面的视频教程,演示了这个三层 cursor 规则系统的完整实施:

视频涵盖内容:
- 在 Cursor IDE 设置中配置全局 cursor 规则
- 创建仓库级规则文件:新方法
.cursor/index.mdc(Rule Type "Always")和传统方法.cursorrules(legacy) - 实施专门任务的上下文感知
.cursor/*.mdc文件 - 演示每个级别如何协同工作以优化 AI 协助
- 故障排除常见问题和优化令牌使用
你将看到整个工作流程的实际操作,从初始设置到高级多级配置,这些配置改变了你与 AI 助手的协作方式。