Reglas de Cursor IDE para IA: Guías para un Asistente de IA Especializado
Cursor IDE implementa tres niveles de reglas:
- Reglas para IA en la configuración de Cursor IDE - reglas base que se aplican globalmente a todos los proyectos
- Archivo
.cursor/index.mdccon Rule Type "Always" - reglas específicas del repositorio (reemplaza el enfoque legacy.cursorrules) - Archivos
.cursor/rules/*.mdc- reglas dinámicas que solo se activan cuando la IA aborda tareas relevantes para su descripción
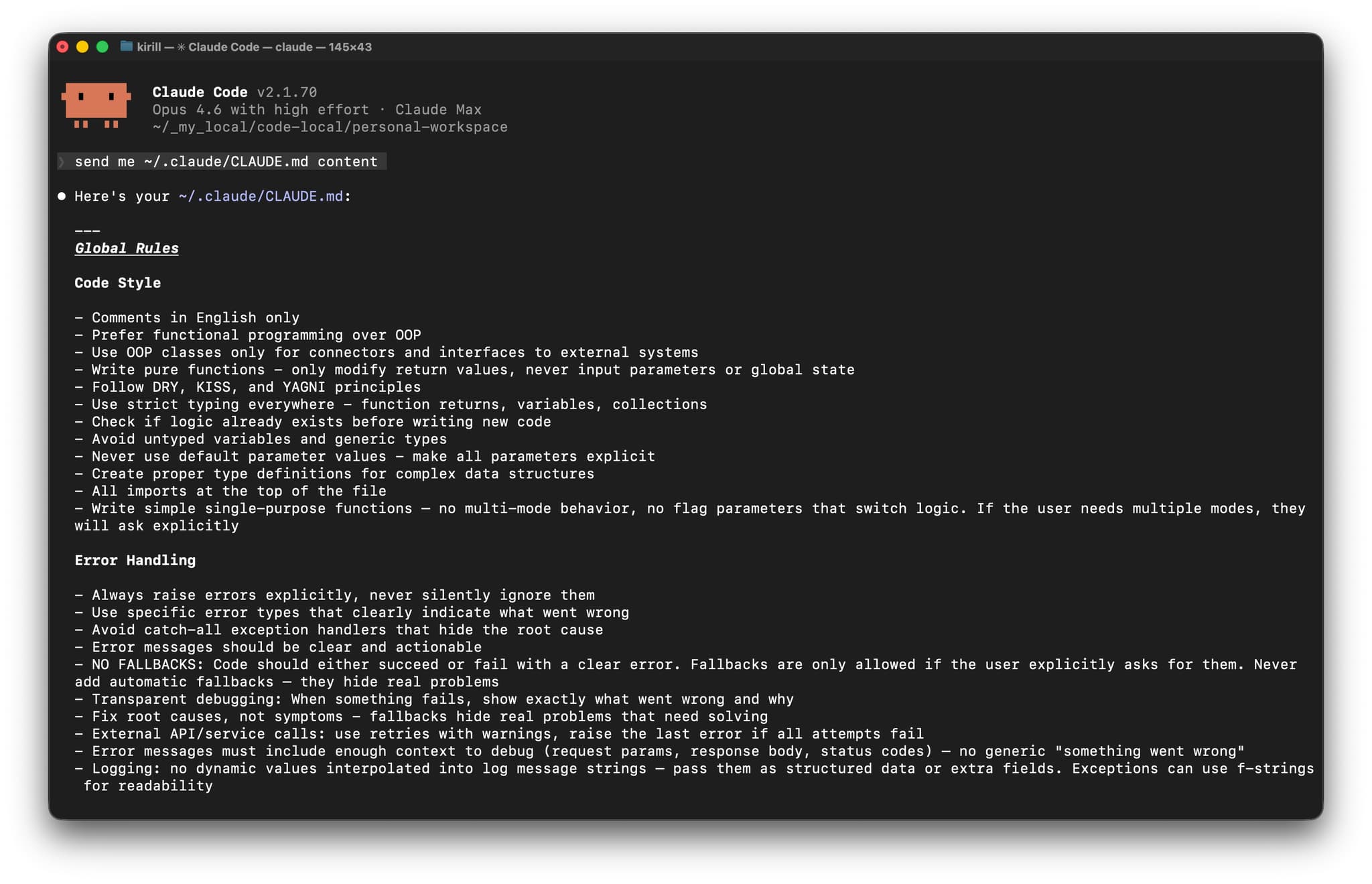
Aquí comparto mis reglas de cursor de nivel base - la configuración global que uso en Cursor IDE. Estas reglas forman la base de todo mi trabajo de desarrollo. Cuando se combinan con reglas a nivel de repositorio y reglas dinámicas, crean un sistema potente que mantiene la calidad del código mientras conserva mis prácticas de desarrollo consistentes.
¿Prefieres un Tutorial en Video? He creado un recorrido completo en video de todo este sistema de reglas de cursor. Mira Ultimate Cursor AI IDE Rules Guide: All 5 Levels and .cursorrules (2025) para ver estas técnicas implementadas paso a paso.

Cómo configurar las reglas de Cursor para un rendimiento óptimo de codificación con IA
Cursor -> Configuración -> Configuración de Cursor -> Reglas para IA:
# Global Rules
## Code Style
- Comments in English only
- Prefer functional programming over OOP
- Use OOP classes only for connectors and interfaces to external systems
- Write pure functions - only modify return values, never input parameters or global state
- Follow DRY, KISS, and YAGNI principles
- Use strict typing everywhere - function returns, variables, collections
- Check if logic already exists before writing new code
- Avoid untyped variables and generic types
- Never use default parameter values - make all parameters explicit
- Create proper type definitions for complex data structures
- All imports at the top of the file
- Write simple single-purpose functions — no multi-mode behavior, no flag parameters that switch logic. If the user needs multiple modes, they will ask explicitly
## Error Handling
- Always raise errors explicitly, never silently ignore them
- Use specific error types that clearly indicate what went wrong
- Avoid catch-all exception handlers that hide the root cause
- Error messages should be clear and actionable
- NO FALLBACKS: Code should either succeed or fail with a clear error. Fallbacks are only allowed if the user explicitly asks for them. Never add automatic fallbacks — they hide real problems
- Transparent debugging: When something fails, show exactly what went wrong and why
- Fix root causes, not symptoms - fallbacks hide real problems that need solving
- External API/service calls: use retries with warnings, raise the last error if all attempts fail
- Error messages must include enough context to debug (request params, response body, status codes) — no generic "something went wrong"
- Logging: no dynamic values interpolated into log message strings — pass them as structured data or extra fields. Exceptions can use f-strings for readability
## Language Specifics
- Prefer structured data models over loose dictionaries (Pydantic, interfaces)
- Avoid generic types like `Any`, `unknown`, or `List[Dict[str, Any]]`
- Use modern package management (pyproject.toml, package.json)
- Leverage language-specific type features (discriminated unions, enums)
## Libraries and Dependencies
- Install in virtual environments, not globally
- Add to project configs, not one-off installs
- When a dependency is installed locally (node_modules, .venv, etc.), read its source code directly even if it's gitignored — this is the best way to understand how a library works
- Update project configuration files when adding dependencies
## Testing
- Respect the current repository testing strategy and existing test suite
- Do not add new unit tests by default
- When tests are needed, prefer integration tests or smoke tests that validate real behavior
- Avoid mocks when real calls are practical
- It is usually better to spend a little money on real API or service calls than to maintain fragile mock-based coverage
- Add only the minimum test coverage needed for the requested change
## Terminal Usage
- Always use non-interactive git diff: `git --no-pager diff` or `git diff | cat`
- Prefer non-interactive commands with flags over interactive ones
## Code Changes
- Matching the existing code style is more important than "correct" or "ideal" style — new code must look like it was written by the same author
- Suggest only minimal changes related to current dialog
- Change as few lines as possible while solving the problem
- Focus only on what user is asking for - no extra improvements
## Documentation
- Code is the primary documentation — use clear naming, types, and docstrings
- Keep documentation in docstrings of the functions/classes they describe, not in separate files
- Separate docs files (in `docs/`) only when a concept cannot be expressed in code — and only one file per topic
- Never duplicate documentation across files — reference other sources instead
- Store knowledge as current state, not as a changelog of modifications

Maximizando la eficiencia con la estrategia de reglas de Cursor en múltiples niveles
Cuando trabajo con las funciones de IA de Cursor IDE, he descubierto que es crucial optimizar las reglas de cursor en los tres niveles. La clave es minimizar el número de tokens (símbolos) enviados al modelo de lenguaje en cada diálogo. Menos tokens para el contexto significa más capacidad para generar respuestas de calidad.
Para más información sobre cómo funcionan las reglas de cursor en Cursor, consulta la documentación oficial de Cursor sobre Reglas para IA.
Flujo de implementación en 3 pasos para las reglas de Cursor
-
Empezar solo con configuración a nivel de IDE
Comienzo con la configuración global de Cursor IDE para establecer preferencias básicas. Esto me permite experimentar con diferentes formulaciones de reglas sin sobrecargar mis repositorios. Reservo este nivel para reglas de cursor verdaderamente universales que aplican a todo mi trabajo de codificación. -
Mover las reglas de Cursor específicas del proyecto al nivel de repositorio
Cuando identifico patrones específicos para una base de código particular o quiero compartir mis directrices de IA con compañeros de equipo, muevo estas reglas de cursor a un archivo.cursor/index.mdccon Rule Type "Always". Esto crea un entendimiento compartido mientras mantengo mi configuración global sencilla. (Nota: el archivo legacy.cursorrulesaún funciona pero ya no se recomienda.) -
Dividir en reglas de Cursor sensibles al contexto cuando sea necesario
Si mis archivos de reglas a nivel de repositorio se vuelven demasiado extensos, los divido en archivos.cursor/*.mdc. Esto reduce el uso de tokens al activar solo las reglas de cursor relevantes cuando se necesitan. Es como darle al modelo de lenguaje más espacio mental para pensar en mi tarea específica en lugar de recordar un montón de directrices irrelevantes.
Mi objetivo es simple: en cualquier conversación con el asistente de IA, darle justo el contexto suficiente para ser útil sin desperdiciar su capacidad en información que no necesita en ese momento.
Ejemplos de reglas de Cursor en repositorios de producción reales
Para mostrar cómo implemento las reglas de cursor en diferentes proyectos, aquí hay algunos ejemplos reales:
Archivos .cursor/index.mdc a nivel de repositorio: estructura e implementación
Mis archivos .cursor/index.mdc con Rule Type "Always" funcionan como un README.md específicamente diseñado para asistentes de IA. Proporcionan contexto sobre el propósito del proyecto, la arquitectura y los patrones de codificación. (Los archivos legacy .cursorrules aún se soportan pero no se recomiendan para nuevos proyectos.)

Ejemplos de repositorios de producción con reglas de Cursor
Nota: Estos ejemplos usan el enfoque legacy .cursorrules que aún funciona. Para nuevos proyectos, se recomienda usar .cursor/index.mdc con Rule Type "Always".
-
repo-to-text: Esta utilidad para convertir repositorios a texto incluye reglas que explican el propósito del proyecto, decisiones de arquitectura y patrones de código a seguir.
-
chatgpt-telegram-bot-telegraf: Para este bot de Telegram, las reglas se centran en la arquitectura del bot, patrones de uso de API y convenciones para manejar mensajes y comandos.
Archivos .cursor/*.mdc sensibles al contexto: cuándo y cómo usarlos
Cuando las reglas a nivel de repositorio se vuelven demasiado extensas, las divido en archivos .cursor/*.mdc específicos de contexto que solo se activan cuando son relevantes.

Ejemplo de implementación de reglas específicas para tareas
Un buen ejemplo es mi repositorio de sitio web personal: website-next-js/.cursor/rules/
En este repositorio, he creado archivos de reglas separados para:
- Flujos de trabajo de gestión de contenido
- Requisitos de optimización de imágenes
- Mejores prácticas de SEO
- Patrones de arquitectura de componentes
- Procedimientos de despliegue
Este enfoque mantiene a la IA enfocada y evita abrumarla con información irrelevante cuando estoy trabajando en tareas específicas.
Inclusión de reglas en medio del diálogo: limitaciones y mejores prácticas
Una limitación importante a tener en cuenta: las reglas .mdc sensibles al contexto funcionan mejor cuando se aplican al inicio de un nuevo diálogo. Si estás en medio de una conversación existente con Cursor IDE y de repente necesitas aplicar una regla especializada (como directrices de consulta de base de datos), la IA puede no acceder automáticamente a ese archivo de reglas. Esto ocurre porque Cursor ya ha establecido el contexto para tu conversación y no siempre reevalúa qué reglas aplicar en medio del diálogo.
En estas situaciones, menciono explícitamente la regla que necesito: "Por favor, sigue nuestras directrices de consulta de base de datos para esta tarea". Esto insta a Cursor a buscar y aplicar la regla relevante. Para tareas críticas que dependen de directrices específicas, encuentro que es más efectivo iniciar un diálogo nuevo donde Cursor detectará y aplicará automáticamente todas las reglas sensibles al contexto desde el principio.
Evolución de las reglas de Cursor: de configuración global a sistemas sensibles al contexto
Mi trayectoria con las reglas de cursor ha evolucionado a través de varias fases:
Fase 1: configuración global del IDE para reglas de Cursor universales
Comencé volcando todo en la configuración de Cursor IDE. Simple pero efectivo al principio. A medida que identifiqué más patrones en mi flujo de trabajo, estas reglas de cursor globales crecieron. Cada nuevo proyecto se benefició, pero la configuración eventualmente se volvió difícil de manejar - demasiadas reglas que no se aplicaban en todas partes.
Fase 2: reglas de Cursor específicas de repositorio para estándares de proyecto
A medida que mi configuración global se sobrecargaba con información irrelevante para el proyecto, cambié a usar reglas a nivel de repositorio. Inicialmente, esto significaba archivos .cursorrules en las raíces de los repositorios (ahora legacy). Este se convirtió en mi enfoque principal, permitiéndome personalizar las reglas de cursor para cada proyecto mientras mantenía estándares consistentes. Hoy en día, el enfoque recomendado es archivos .cursor/index.mdc con Rule Type "Always".
Fase 3: reglas de Cursor dinámicas sensibles al contexto para tareas especializadas
Cuando Cursor IDE introdujo las reglas dinámicas .cursor/*.mdc, reestructuré todo. Estas reglas de cursor sensibles al contexto solo se activan cuando la IA está realizando tareas relevantes. Esto me permitió:
- Mantener la configuración global mínima y ampliamente aplicable
- Usar
.cursor/index.mdccon Rule Type "Always" para estándares a nivel de proyecto (reemplazando legacy.cursorrules) - Crear archivos
.cursor/*.mdcenfocados para tareas especializadas
Este enfoque por capas proporciona orientación justo a tiempo a la IA basada en lo que estoy trabajando actualmente, eliminando el ruido y mejorando la relevancia de su asistencia.
La evolución refleja mi creciente comprensión de cómo colaborar efectivamente con asistentes de IA - comenzando de manera amplia y refinando progresivamente hacia reglas de cursor sensibles al contexto y específicas para tareas que maximizan la efectividad de la IA.
Comparación completa de los niveles de reglas de Cursor: Global vs Repositorio vs Sensible al contexto
Aquí hay una comparación rápida de los tres niveles de reglas de cursor en Cursor IDE:
| Característica | Configuración global del IDE | Reglas de repositorio (.cursor/index.mdc "Always") | Reglas sensibles al contexto (.cursor/*.mdc) |
|---|---|---|---|
| Alcance | Todos los proyectos | Repositorio específico | Tareas o contextos específicos |
| Visibilidad | Solo tú (configuración local) | Todo el equipo a través del repositorio | Todo el equipo a través del repositorio |
| Persistencia | Se mantiene a través de proyectos | Vinculada al repositorio | Vinculada al repositorio |
| Activación | Siempre activa | Siempre activa para el repositorio | Solo cuando es relevante para la tarea actual |
| Mejor para | Reglas de cursor universales | Patrones de arquitectura del proyecto | Conocimiento de dominio especializado |
| Eficiencia de tokens | Baja (siempre presente) | Media (siempre presente para el proyecto) | Alta (solo se carga cuando es necesario) |
| Ubicación de configuración | Interfaz de configuración de Cursor | Archivo .cursor/index.mdc | Directorio .cursor/rules/ |
| Portabilidad | Requiere configuración manual en cada dispositivo | Automática con la clonación del repositorio | Automática con la clonación del repositorio |
| Soporte legacy | N/A | .cursorrules aún funciona (legacy) | N/A |
Este enfoque de múltiples niveles te permite optimizar el uso de tokens mientras mantienes una orientación consistente en diferentes escenarios.
Guía paso a paso: implementando reglas de Cursor en tu flujo de trabajo de desarrollo
Ahora que he compartido la teoría detrás de mi enfoque de las reglas de cursor, veamos cómo puedes implementar un sistema similar para tu propio trabajo de desarrollo.
Configurando reglas de Cursor globales para asistencia de IA
Para configurar tus propias reglas de cursor globales en Cursor IDE:
- Abre Cursor IDE y ve a Configuración (botón de la esquina superior derecha)
- Navega a Configuración de Cursor > Reglas para IA
- Agrega tus directrices principales en la estructura formateada que viste anteriormente
- Mantén las reglas de cursor globales enfocadas en estándares de codificación universales que apliquen a todos los proyectos
- Prueba con instrucciones simples para ver cómo responde la IA a tus instrucciones
Gestionando eficientemente la configuración local de Cursor IDE
La clave es encontrar un equilibrio - muy pocas reglas y la IA no entenderá tus preferencias; demasiadas y desperdiciarás tokens en contexto irrelevante.
Es importante notar que esta configuración se almacena localmente en tu instalación de Cursor IDE. Tus colegas no verán esta configuración a menos que la configuren en sus propias máquinas. Además, si usas Cursor IDE en múltiples computadoras (como cuentas personales y de trabajo separadas), necesitarás configurarlas manualmente en cada instalación.
Creando archivos .cursor/index.mdc a nivel de repositorio para equipos de proyecto
Para la configuración a nivel de proyecto:
- Crea un archivo
.cursor/index.mdcen tu repositorio - Establece Rule Type como "Always" en la interfaz de Cursor (o especifica manualmente en el archivo)
- Comienza con una breve descripción general del proyecto (qué hace el proyecto, stack tecnológico, etc.)
- Documenta patrones de arquitectura que la IA debería entender
- Incluye convenciones de código específicas para este proyecto
- Mantén el archivo por debajo de 100 líneas para un uso óptimo de tokens
Nota: Los archivos legacy .cursorrules aún funcionan pero ya no son el enfoque recomendado.
Plantilla de reglas de repositorio para proyectos de Cursor IDE
Aquí hay una plantilla mínima para empezar:
# Proyecto: [Nombre del Proyecto]
## Visión general
- Propósito: [Breve descripción]
- Stack: [Tecnologías clave]
- Arquitectura: [Patrón clave - MVC, microservicios, etc.]
## Patrones de código
- [Lista de patrones específicos del proyecto]
## Requisitos de estilo
- [Directrices de estilo específicas del proyecto]
Creando archivos de reglas .mdc sensibles al contexto para tareas especializadas
Para una configuración más avanzada:
- Crea un directorio
.cursor/rules/en tu repositorio - Agrega archivos
.mdcespecíficos para diferentes contextos - Nombra los archivos de manera descriptiva basándote en su propósito
- Mantén cada archivo enfocado en una preocupación específica
- Incluye una breve descripción al principio de cada archivo para ayudar a la IA a entender cuándo aplicar estas reglas
Creando reglas de Cursor: métodos manual vs interfaz de IDE
Puedes crear estos archivos manualmente, o usar la interfaz de Cursor IDE:
- Ve a Configuración > Reglas
- Haz clic en "Agregar regla"
- Ingresa un nombre y descripción para tu regla
- Agrega el contenido de tu regla personalizada
- Guarda la regla, y Cursor creará el archivo
.mdcapropiado en tu repositorio
Ambos enfoques funcionan igualmente bien - la creación manual de archivos te da más control sobre la estructura del archivo, mientras que la interfaz de Cursor ofrece una experiencia más guiada.
Ejemplo de archivo de regla de Cursor para desarrollo de React
Por ejemplo, un archivo de reglas de componentes de React podría verse así:
# Directrices de componentes de React
Estas reglas se aplican cuando se trabaja con componentes de React en este proyecto.
## Estructura de componentes
- Componentes funcionales con interfaces TypeScript para props
- Hooks personalizados para gestión de estado complejo
- Styled components para estilización
## Convenciones de nombres
- Archivos de componentes: PascalCase.tsx
- Archivos de hooks: use[Nombre].ts
- Archivos de estilos: [nombre].styles.ts
Beneficios mensurables de usar reglas de Cursor para codificación asistida por IA
Después de implementar este sistema de reglas de cursor en múltiples niveles, he visto mejoras tangibles en varias dimensiones.
Mejora de métricas de calidad de código a través de reglas de Cursor consistentes
El beneficio más inmediato ha sido una calidad de código consistente. Al codificar mis preferencias en reglas de cursor, la IA genera código que:
- Sigue los principios de programación funcional de manera consistente
- Implementa un manejo de errores adecuado sin instrucciones explícitas
- Incluye tipado apropiado sin recordatorios constantes
- Mantiene convenciones de nomenclatura consistentes en todo el código
Esto se traduce en menos comentarios de revisión y menos tiempo dedicado a correcciones de estilo. Un proyecto vio una reducción del 50% en comentarios de PR relacionados con el estilo después de implementar estas reglas de cursor.
Colaboración de equipo mejorada con reglas de Cursor compartidas
Cuando trabajo con equipos, las reglas de cursor crean un entendimiento compartido:
- Los nuevos miembros del equipo entienden rápidamente las expectativas a través de los archivos de reglas a nivel de repositorio
- La colaboración multifuncional mejora ya que tanto ingenieros como no ingenieros pueden hacer referencia a las mismas reglas
- El intercambio de conocimientos ocurre automáticamente a medida que la IA aplica las mejores prácticas de forma consistente
He encontrado esto especialmente valioso al incorporar desarrolladores junior - reciben retroalimentación inmediata sobre las mejores prácticas sin esperar a las revisiones de código.
Ganancias de productividad por interacciones optimizadas con la IA de Cursor IDE
Los números hablan por sí mismos:
- Alrededor del 60% de reducción en el tiempo dedicado a explicar estándares de código a nuevos miembros del equipo
- Alrededor del 35% más rápido en envíos iniciales de PR con menos ciclos de revisión
- Alrededor del 40% menos de commits de "corrección de estilo" desordenando el historial de git
Pero la métrica más valiosa ha sido el ancho de banda mental. Al descargar las preocupaciones de estilo a la IA, los desarrolladores pueden concentrarse en resolver el problema real en lugar de recordar reglas de formato.
Técnicas avanzadas de reglas de Cursor para desarrolladores profesionales
A medida que te sientas cómodo con las estructuras básicas de reglas, prueba estas técnicas avanzadas para refinar aún más tu experiencia de asistencia de IA.
Reglas de Cursor específicas para tareas especializadas en escenarios comunes de desarrollo
He encontrado que los archivos de reglas de cursor especializados son particularmente efectivos para estos escenarios:
Reglas de pruebas (directrices-pruebas.mdc)
- Respeta la estrategia de pruebas existente del repositorio
- Prefiere cobertura de integración y smoke tests en lugar de agregar nuevos unit tests
- Evita mocks cuando las llamadas reales sean prácticas
- Prefiere gastar un poco de dinero en llamadas reales antes que construir pruebas frágiles basadas en mocks
- Define solo la cobertura mínima necesaria para la tarea actual
Reglas de integración de API (estandares-api.mdc)
- Expectativas de manejo de errores
- Patrones de lógica de reintentos
- Estándares de flujo de autenticación
Reglas de gestión de estado (patrones-estado.mdc)
- Convenciones de nomenclatura de acciones Redux
- Directrices de normalización de estado
- Patrones de manejo de efectos secundarios
Al dividir estas preocupaciones, cada archivo se mantiene enfocado y solo se activa cuando es relevante para tu tarea actual.
Optimizando el uso de tokens de IA en reglas de Cursor
Para maximizar la ventana de contexto efectiva de la IA:
- Prioriza la recencia: Coloca las reglas más importantes al principio o al final de los archivos
- Usa estructura jerárquica: Comienza con principios generales, luego pasa a los específicos
- Elimina la redundancia: No repitas la misma regla en múltiples lugares
- Usa lenguaje conciso: Escribe reglas en viñetas en lugar de párrafos
- Aprovecha el formato markdown: Usa encabezados para distinguir entre categorías de reglas
Como regla general, si un archivo de reglas excede las 100 líneas, probablemente está tratando de hacer demasiado y debería dividirse en componentes más enfocados.
Solución de problemas comunes de reglas de Cursor y soluciones
Cuando tus reglas de cursor no producen los resultados esperados:
- Conflictos de reglas: Verifica si tienes directrices contradictorias en diferentes niveles
- Demasiado genéricas: Haz las reglas de cursor más específicas con ejemplos concretos
- Demasiado específicas: Las reglas excesivamente estrechas podrían no generalizarse a escenarios similares
- Limitaciones de tokens: Si las reglas de cursor están siendo truncadas, prioriza y simplifica
- Contexto faltante: La IA podría necesitar contexto de archivo adicional para aplicar las reglas correctamente
- Sobrecarga de reglas: Cuando demasiadas reglas de cursor aparecen en el mismo diálogo, el modelo tiene dificultades para recordar y seguir todas ellas simultáneamente - prioriza las más importantes
He descubierto que revisar el código generado con mis reglas de cursor y refinarlas iterativamente conduce a una mejora continua en la calidad de la asistencia de IA.
Cursor IDE vs otros asistentes de codificación con IA: comparación de enfoques de configuración
Aunque Cursor tiene un sistema particularmente bien diseñado para reglas, otros asistentes de codificación con IA tienen enfoques similares para la personalización:
- GitHub Copilot ofrece
.github/copilot/settings.ymlpara configuración a nivel de proyecto - JetBrains AI Assistant tiene fragmentos y plantillas a nivel de proyecto
- VS Code con varias extensiones de IA admite configuraciones de espacio de trabajo y archivos de personalización
La economía de tokens: maximizando el rendimiento de IA en todas las herramientas
Lo que une todos estos enfoques es un principio fundamental: minimizar el uso de tokens es esencial para obtener resultados óptimos. Independientemente de qué asistente de codificación con IA utilices, proporcionar justo el contexto suficiente sin abrumar al modelo es la clave del éxito.
La economía de tokens funciona de la misma manera en todas las herramientas basadas en LLM:
- Cada palabra que agregas a tus instrucciones consume tokens
- Los tokens utilizados para instrucciones reducen el contexto disponible para la comprensión del código
- Una guía extremadamente verbosa conduce a rendimientos decrecientes
Así que ya sea que estés usando el sistema de reglas de tres niveles de Cursor u opciones de configuración de otra herramienta, siempre apunta a ser preciso y conciso. Enfoca tu guía en los patrones y preferencias específicos que más importan, y deja que la IA maneje el resto.
La verdadera ventaja no está en qué herramienta proporciona más opciones de personalización, sino en cómo utilizas cuidadosamente las opciones disponibles para comunicar tus expectativas sin desperdiciar tokens en verbosidad innecesaria.
Tutorial en Video: Mira la Implementación Completa de Reglas de Cursor IDE
Si prefieres aprender visualmente, he creado un tutorial completo en video que demuestra la implementación completa de este sistema de reglas de cursor de tres niveles:

El video cubre:
- Configuración de reglas globales de cursor en los ajustes de Cursor IDE
- Creación de archivos de reglas específicos del repositorio: nuevo enfoque
.cursor/index.mdccon Rule Type "Always" y enfoque legacy.cursorrules(tradicional) - Implementación de archivos
.cursor/*.mdcsensibles al contexto para tareas especializadas - Demostración de cómo cada nivel funciona en conjunto para optimizar la asistencia de IA
- Solución de problemas comunes y optimización del uso de tokens
Verás todo el flujo de trabajo en acción, desde la configuración inicial hasta configuraciones multinivel avanzadas que transforman cómo colaboras con asistentes de IA.